
英语原文共 4 页,剩余内容已隐藏,支付完成后下载完整资料
在线社交网络营销中的数据挖掘响应分析
杰西瑟
华沙经济学院工商管理学院,波兰华沙,jerzy.surma@gmail.com
摘要
在线社交网络的商业使用是近年来迅猛发展的自然结果。特定社区成员的信息可以作为正确识别其需求的基础,从而调整个性化营销信息。在本研究中,我们将讨论分类和回归树(Camp;RT)模型,用于识别在线社交网络用户可能对营销活动作出响应。该模型旨在利用先进的数据挖掘方法,使企业能够利用社交网络和相关的研究问题,关系属性在客户行为分析中的重要性。本文的研究证实了数据挖掘技术在营销活动优化中的应用。反应率的显著提高证明了这一点。我们还证明了关系属性对用户描述的扩展并没有改进基于单个属性的经典方法。
关键词:在线社交网络分析、数据挖掘、营销响应分析
一、介绍
时下我们可以把数据注册在社交网络的背景下给定用户相关数据(如年龄、性别、居住地等)-个人数据和数据描述之间的关系成员(如与其他用户联系的频率、数量的邀请,博客上的评论数量等)-关系数据。所描述的数据类型具有声明性或行为性特征,即由真实的用户行为产生。大型用户群体留下的数据的行为维度与他们的数量有关,例如,在长期和密集的活动中,它允许我们进行有价值的统计社交网络分析[1]。在这个领域中使用数据挖掘似乎是一种很有前途的方法。
研究环境是Biznes。Net——许多波兰社交网络之一,帮助创建和维护业务关系。这个虚拟社区的成员身份让用户有机会与业务伙伴见面,并通过编辑他们的个人资料、撰写博客或参加许多活动来展示他们的专业经验指定的组。此外,参与可以为用户提供有价值的商业活动信息,如培训或研讨会,从而促进用户的个人发展。
在本文的下一部分,我们将提出一个基于决策树Camp;RT[3]的分类分析模型,以便能够预测营销信息[4]的反应。该模型是使用个体和关系属性构建的。
二、相关工作
本研究的主要概念是互动营销中在线社交网络分析的业务维度。在过去的十年中,我们可以观察到虚拟社区的迅速普及,在经济学[5]和组织语境[6]中,虚拟社区可以被视为一个优雅而有价值的社会研究环境。在线社交网络中大量可用的行为数据为数据挖掘技术带来了知识发现的机会。Han和Kamber[7]描述了该领域的概况和研究。
三、问题描述
应该指出的是,自从新世纪开始,社交网络现象已经对我们的日常生活产生了巨大的影响。参与虚拟社区的人越多,我们对在线网络的潜在商业价值的期望就越大。根据这些事实,我们研究的目的是指出一种可能的途径,可以给我们带来可衡量的回报与在线社交网络考试。在我们的实验中,我们利用Camp;RT模型,这是一个足够的方法来分析基于二元反应的营销活动。但是,考虑到研究环境的特殊性,本文分别讨论了关系(网络)属性在Camp;RT模型构建中的参与问题。
首先,我们将介绍研究环境的特点和数据集规范。然后给出实验假设。
A.社交网络和数据集规范
Net规范由一组度量标准描述,这些度量标准是典型的“小世界”系统[8]的度量标准,其中大多数顶点属于巨型组件(从3025到2828),任意两个用户之间的平均路径相对较短(3.53)。
初始数据集由62个属性组成,包含关于19593个网络成员的信息。这些属性是用支持Biznes的关系数据库中的可用信息准备的。网络社交网络。它们既有数量上的,也有分类上的。所有的预测因子都可以被理解为陈述性的(例如性别、年龄)以及行为。这意味着它们代表了用户在网络环境中所采取的实际行动。数据集的这种行为方面在我们的研究中尤为重要。根据这一事实,我们假设某些分类属性的缺失值可以被感知为一个给定的值—NULL,可以解释为用户有意识地隐藏一些信息。所有获得的数据都是匿名的,用户只能通过其唯一的id号进行标识。正如前面提到的,所有属性都可以分为两组:个体属性和关系属性。第一组属性只对应于特定的用户。在第二组中,我们找到了描述网络成员之间所有现有关系的谓词。
表一 主要网络指标
|
指示器 |
价值 |
|
成员 |
19593 |
|
顶点总数 |
3025 |
|
数量的组件 |
90 |
|
巨大分量密度中的顶点数 |
2828 |
|
密度 |
0,002 |
|
普通朋友数量 |
5.88 |
|
中间性中心 |
0.21 |
|
聚类系数 |
0.23 |
|
平均路径长度 |
3.53 |
B .实验假设
在我们的研究中,Camp;RT模型被用来建立一个有效的营销活动接受者分类器。预测与实际反应可分为四类:真阳性、真阴性、假阳性和假阴性[4]。真正的类是那些被模型正确识别为真正对我们的报价感兴趣或对接收到的广告漠不关心的用户。错误的类是那些对我们的产品有正面或负面兴趣的用户,而实际情况恰恰相反。
表二 类别的分类
|
观察量 |
分类 |
||
|
真 |
假 |
||
|
真 |
真阳性 |
假阴性 |
|
|
假 |
假阳性 |
真阴性 |
|
表三 成本-收入-利润汇总
|
收入 |
成本 |
利润 |
|
|
真阳性 |
z |
0.01z |
0.99z |
|
真阴性 |
0 |
0 |
0 |
|
假阳性 |
0 |
0.01z |
-0.01z |
|
假阴性 |
0 |
Z |
-z |
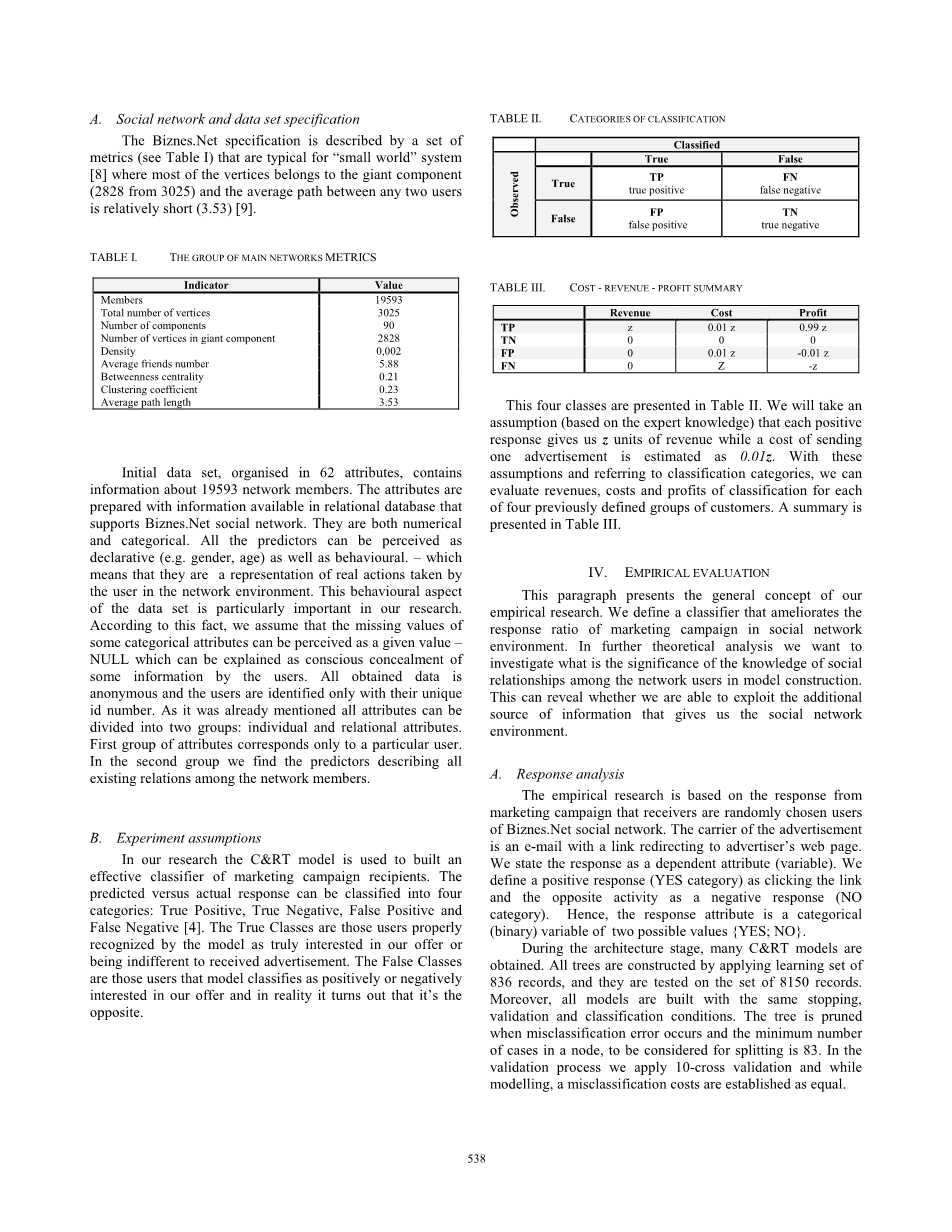
表二给出了这四个类。我们将假设(基于专家知识),每个正面响应为我们带来z单位的收入,而发送一个广告的成本估计为0.01z。有了这些假设,并参照分类类别,我们可以对前面定义的四组客户中的每一组评估分类的收入、成本和利润。摘要见表三。
四、实证评估
这一段介绍了我们实证研究的一般概念。我们定义了一个分类器来改善社交网络环境下营销活动的响应率。在进一步的理论分析中,我们想探究网络用户之间的社会关系知识在模型构建中的意义。这可以揭示我们是否能够利用提供给我们社交网络环境的额外信息来源。
A.响应分析
实证研究基于市场营销活动的响应,即受众是随机选择的Biznes用户。网络社交网络。广告的载体是一封电子邮件,其中的链接重定向到广告主的网页。我们将响应声明为一个依赖属性(变量)。我们将积极响应(YES类别)定义为单击链接,将相反的活动定义为消极响应(NO类别)。因此,response属性是一个包含两个可能值{YES;没有}。
在体系结构阶段,得到了许多Camp;RT模型。所有的树都是通过应用836条记录的学习集构建的,并在8150条记录集上进行测试。此外,所有模型都是在相同的停止、验证和分类条件下建立的。当错误分类错误发生时,该树被剪枝,一个节点中需要考虑的最小情况数为83。在验证过程中,我们采用了10-交叉验证,在建模时,错误分类的代价是相等的。
表四 在没有分类器的情况下和有分类器的情况下进行了营销模拟
|
组随机选择 |
由Camp;RT模型选择 |
总结 |
|
|
样本大小 |
1918 |
2052 |
3970 |
|
响应 |
71 |
131 |
202 |
|
响应比例 |
3.70% |
6.38% |
5.1% |
Camp;RT算法实现允许我们生成一个分类器,营销活动的反应几乎翻了一番(见表4)。通过实现这个模型在测试集上我们获得6.4%的回应率是更好的(显著性水平为0.01)随机响应的结果(3.7%)。见Surma和Furmanek论文[10]对实验的详细描述。此外,通过分析选择的树,我们可以观察到,最好的预测器是days_from_last_login属性。这种情况有其合理的解释,因为它表示最活跃的用户。所有进一步的分歧都会带来更好的调整。研究结果表明,数据挖掘方法是一种能够带来业务维度有形利润的工具。
B.关系属性分析
在构建了有效的分类器之后,我们将重点考察个体属性和关系属性在Camp;RT模型构建中的重要性。我们想要探索的是,利润是否能够以及如何能够让我们认识到不同的商业社区之间的社会互动。网络成员。
表五 实验中属性利用的类型
|
类型 |
序号 |
<strong 剩余内容已隐藏,支付完成后下载完整资料</strong 资料编号:[445102],资料为PDF文档或Word文档,PDF文档可免费转换为Word |

