
英语原文共 7 页,剩余内容已隐藏,支付完成后下载完整资料
防止智能机器行为异常
【摘要】使用机器学习算法的智能机器无处不在,从简单的数据分析和模式识别工具到在各种任务中实现超人性能的复杂系统。因此,确保它们不会表现出不良行为——例如,不会对人类造成伤害——是一个紧迫的问题。我们提出了一个通用且灵活的框架来设计机器学习算法。这个框架简化了指定和调节不良行为的问题。为了证明这个框架的可行性,我们用它来创建机器学习算法,在我们的实验中排除了标准机器学习算法导致的危险行为。我们设计机器学习算法的框架简化了机器学习的安全和负责任的应用。
机器学习算法对现代社会的影响越来越大。地理学家用它们来预测山体滑坡(1),生物学家用它们来研制艾滋病毒疫苗(2);它们还影响犯罪感测(3),控制自动交通工具(4),并促进医学进步(5)。因此,最大似然算法造成伤害(包括灾难性伤害)的可能性是一个紧迫的问题(6)。尽管这个问题很重要,但是当前的最大似然算法并没有为用户提供一种有效的方法来排除不良行为,这使得最大似然算法的安全和负责任的使用变得困难。我们引入了一个设计最大似然算法的框架,允许用户容易地定义和调节不良行为。这个框架没有解决给智能机器灌输道德或类人价值观的问题(7),也没有解决避免用户从未考虑过的不良行为的问题(8)。相反,它为表现出不良行为的最大似然算法问题提供了一种补救方法,因为它们的用户没有有效的方法来指定和约束这种行为。
当前设计最大似然算法的标准方法(我们称之为标准最大似然方法)的第一步是从数学上定义算法应该做什么。在抽象层次上,这个定义在ML的所有分支上是相同的:在可行集q内找到一个解q*,它使目标函数f: Q → ℝ.最大化也就是说,该算法的目标是在
注意,该算法不知道任何q isin; Q的f(q)(例如,真实均方误差);它只能根据数据进行推理(例如,通过使用样本均方误差)。
标准最大似然法的一个问题是最大似然算法的用户必须在可行集或目标函数中对算法的行为进行约束编码。在目标函数[中编码约束,例如,使用软约束(9)或稳健和风险敏感的方法(10)]需要广泛的领域知识或额外的数据分析来适当地平衡主要目标函数和约束的相对重要性。类似地,在可行集[中编码约束(例如,使用硬约束(9)、机会约束(11)或稳健优化方法(12))需要从其采样可用数据的概率分布的知识,这通常是不可用的。
我们设计最大似然算法的框架允许用户更容易地约束算法的行为,而不需要广泛的领域知识或额外的数据分析。这是通过将确保算法良好运行的负担从算法用户转移到算法设计者来实现的。这一点很重要,因为最大似然算法被那些在他们的领域是专家,但在最大似然和统计学方面可能不是专家的人用于关键应用。
我们现在定义我们的框架。假设D,称为数据,是最大似然算法的输入。例如,在分类设置中,D不是单个标记的训练示例,而是所有可用的标记训练示例。d是一个随机变量,也是我们在后面关于概率的陈述中随机的来源。最大似然算法是函数a,其中a(D)是在数据D上训练时算法输出的解。假设Q是最大似然算法的所有可能解的集合算法可以输出。我们的框架从数学上定义了算法应该做什么,允许用户直接对算法返回的解a(D)进行概率约束。这与标准ML方法不同,在标准ml方法中,用户只能通过重新限制或修改可行集q或目标函数f来间接约束a(D)。具体而言,使用我们的框架构建的算法被设计为满pr(g(a(d)le;0)ge;1-d形式的约束,其中g: Q → ℝ定义了不期望行为的度量(如后面的示例所示), d isin; [0,1]限制了不期望行为的容许概率。
请注意,在这些约束中,D是随机性的唯一来源;我们用大写非字母来表示随机变量,以表明在概率和期望状态中哪些项是随机的。因为这些约束定义了哪些算法a是可接受的(而不是哪些解q是可接受的),所以它们必须在算法设计期间而不是在应用算法时得到满足。这将确保算法性能良好的责任从用户转移到了设计者身上。
使用我们的框架设计最大似然算法包括三个步骤:
1)定义算法设计过程的目标。算法的设计者写一个数学表达式来表达一个目标,特别是设计者希望得到的算法所具有的属性。这个表达式有以下形式,我们称之为一个谢顿优化问题,源自一个虚构的人物(13):
这里A是设计者将考虑的所有算法的集合,f:A→ ℝ现在是量化算法效用的目标函数,我们考虑n ge; 0个约束,每个约束由一个元组(gi,di)定义,其中i isin; {1,hellip;,n}。请注意,这与标准的最大似然法不同:在标准的最大似然法中,公式1定义了算法的目标,即产生一个具有给定属性集的解,而在我们的框架中,公式2定义了设计者的目标,即产生一个具有给定属性集的算法。
2)定义用户将使用的界面。用户应该有自由指定一个或多个gi来捕获用户自己对不良行为的定义。这要求算法a与许多不同的gi定义兼容。因此,设计者应该指定算法将使用的gi的可能定义的类别兼容,并且应该为用户提供一种方法来告诉算法应该使用什么样的gi定义,而不需要用户知道甚至任何q isin; Q的值gi(q)的分布。下面,我们提供如何实现这一点的例子。
3)创建算法。设计者创建一个算法a,这是一个(可能近似的)方程的解。公式2来自步骤1,并允许在步骤2中选择gi类别。在实践中,设计者很少提出无法改进的算法,这意味着他们可能只能找到公式2方程的近似解。我们的框架考虑到了这一点,要求a只满足概率约束,同时试图优化f;我们称这种算法为谢顿算法。我们称一个算法为准谢顿算法,如果它依赖于合理但错误的假设,如诉诸中心极限定理。关于准谢顿算法的优点和局限性的进一步讨论见(14)。
一旦设计了谢顿算法,用户可以通过指定一个或多个gi(属于上述步骤2中选择的gi类别)来应用该算法,以捕获用户对不良行为的期望定义,并指定di,即以gi为特征的不良行为的最大容许概率。
为了展示我们框架的可行性,我们用它来设计回归、分类和强化学习算法。限制回归和分类算法的行为是很重要的,因为,例如,它们已经被用于医学应用,在这些应用中,不良行为可能会延迟癌症诊断(15),并且因为它们已经被证明有时会导致种族主义、性别歧视和其他歧视行为(3,16)。类似地,强化学习算法已经被提议用于不良行为可能导致经济损失(17)、环境破坏(18)甚至死亡(19)的应用。我们下面介绍的谢顿算法和应用是说明设计谢顿算法是可能的和容易处理的,它可以解决重要的问题。请注意,这些只是作为原则的证明;这项工作的主要贡献是框架本身,而不是任何特定的算法或应用。就像分类算法(20)在威斯康星乳腺癌数据集(21)中的常见应用一样,这些应用将我们的最大似然算法定义为医学专家和领域知识的再搜索者可以应用的工具(22),但并不意味着我们所学的解决方案(分类器或pol-icies)应该按原样部署到任何特定的现实问题中。
我们设计的回归算法试图最小化其预测的均方误差,同时以高概率确保感兴趣的统计量g(Q)为
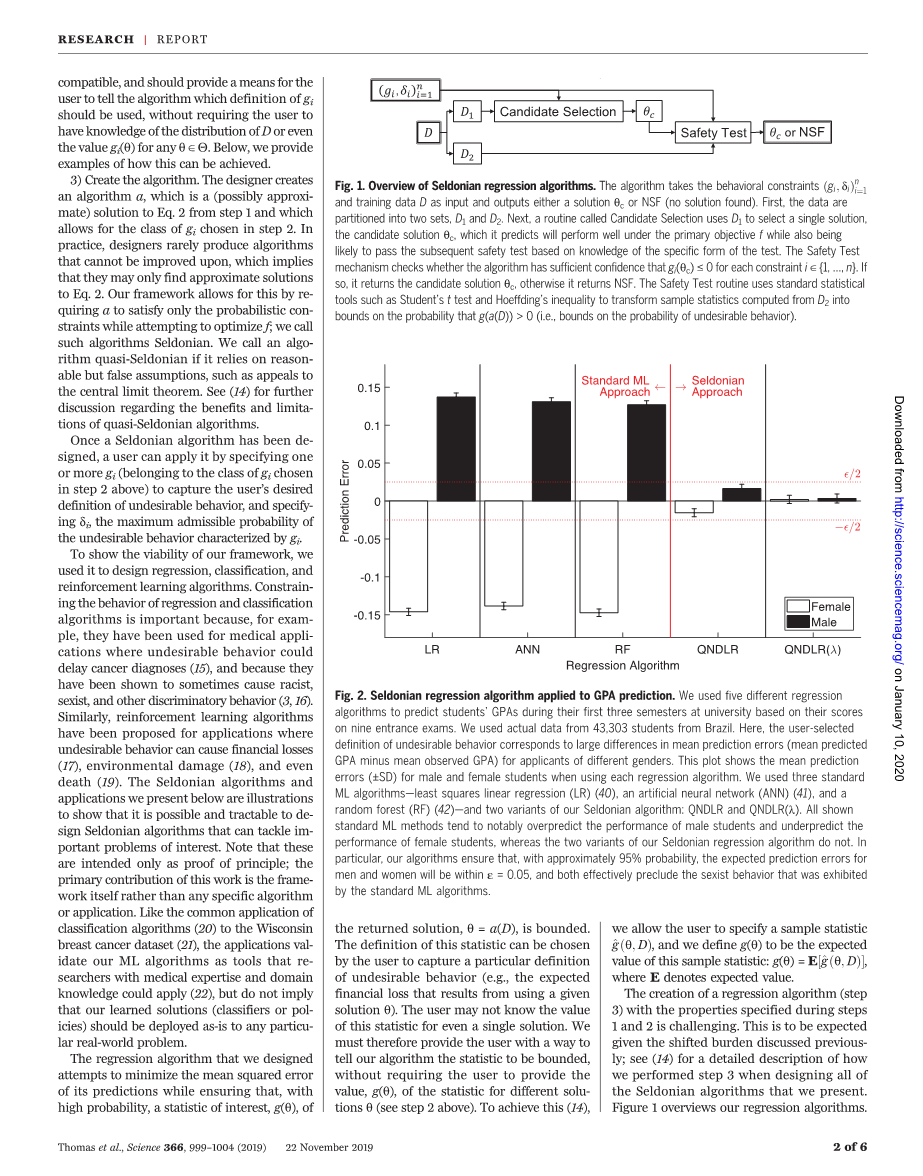
图1 谢顿回归算法概述
该算法采用行为约束gi;将数据1和培训数据D作为输入,并输出解决方案qc或NSF(未找到解决方案)。首先,数据被分成两组,D1和D2。接下来,一个名为候选方案选择的例程使用D1来选择一个方案,即候选方案qc,它预测该方案将在主要目标f下表现良好,同时还可能通过基于特定试验形式的知识的后续安全试验。安全测试机制检查算法对于每个约束i isin; {1,hellip;,n}是否有足够的置信度gi (qc) le; 0。如果是,则返回候选溶液qc,否则返回NSF。安全测试例程使用标准统计工具,如学生t检验和霍夫丁不等式,将从D2计算的样本统计数据转换为g(a(D)) gt; 0的概率界限(即,不良行为概率的界限)。
图2谢顿回归算法在GPA预测中的应用
我们使用了五种不同的回归算法,根据学生在九次入学考试中的分数来预测他们在大学前三个学期的平均绩点。我们使用了来自巴西的43303名学生的实际数据。这里,用户选择的不良行为定义对应于不同性别申请人的平均预测误差(平均预测平均成绩减去平均观察平均成绩)的巨大差异。该图显示了使用每种回归算法时男女学生的平均预测误差。我们使用了三种标准最大似然算法——最小二乘线性回归(40)、人工神经网络(41)和随机森林(42)——以及谢顿算法的两种变体:QNDLR和QNDLR(1)。所有显示的标准最大似然方法都倾向于显著高估男生的成绩,低估女生的成绩,而我们的谢顿回归算法的两个变体则没有。特别是,我们的算法确保,在大约95%的概率下,男性和女性的预期预测误差将在e = 0.05以内,并且两者都有效地排除了标准最大似然算法所表现出的性别歧视行为。
返回的解q = a(D)是有界的。该统计的定义可以由用户选择,以捕获不期望行为的特定定义(例如,使用给定解决方案q导致的预期财务损失)。用户可能甚至不知道单个解决方案的统计值。因此,我们必须向用户提供一种方法来告诉我们的算法统计量是有界的,而不要求用户提供不同解q的统计量的值g(q)(见上面的步骤2)。为了实现这一点(14),我们允许用户指定一个样本统计量g(q,d) ,我们定义g(q)为样本统计的期望值:g(q)=E[g(q,d)],其中E表示期望值。
创建具有步骤1和2中指定的属性的回归算法(步骤3)具有挑战性。考虑到前面讨论的转移负担,这是可以预料的;请参阅(14)了解我们在设计所有谢顿算法时如何执行第3步的详细描述。图1概述了我们的回归算法。
最近为回归任务中的算法公平性而设计的方法(23),与我们自己的方法并行开发,没有给用户选择他们自己想要的不良行为定义的自由,也没有为避免这种行为提供保证。
我们将谢顿回归算法的一个变体应用于预测学生在大学前三个学期的平均成绩的问题,该问题基于他们在九次入学考试中的分数;我们使用了一个样本统计数据来描述一种形式的歧视(性别歧视)。
请注意,我们的算法并不特定于所选择的判别标准;关于公平的其他定义的讨论见(14)。图2显示了这个实验的结果,显示了使用标准最大似然法设计的常用回归算法可以歧视女性学生在申请时不考虑公平。相反,用户可以使用我们的谢顿回归算法很容易地限制图2中观察到的性别歧视行为。
图3 应用于GPA预测的谢顿分类算法
我们应用分类算法来预测学生的平均绩点是否会高于3.0。阴影区域代表超过250次试验。标有“标准”的曲线对应于使用标准最大似然法设计的通用分类算法;公平学习和公平约束的多条曲线对应于每个算法的不同超参数设置(14)。每一行对应一个不同的公平定义:(一)不同的影响,(二)人口均等,(三)机会均等,(四)均等的优势,(五)预测平等。所有图的水平轴对应于数量训练数据和对数标度。左栏显示训练分类器的准确性,中栏显示每个算法返回一个解的概率(非谢顿算法总是返回解),右栏显示每个分类器违反行为约束的概率。当显示每个算法的失败率时,水平虚线对应于100d%,其中d = 0.05。在所有情况下,谢顿算法和准谢顿算法返回的解决方案使用了合理数量的数据(中心),这样做没有显著的准确性损失(左),并且是唯一可靠地执行所有五个公平定义的算法(右)。
为了强调谢顿算法与公平的各种定义兼容,并使我们的研究更好地与当前最先进的公平感知最大似然算法相对应,我们提出了谢顿分类算法(14)。这种分类算法与我们的回归算法的不同之处在于它的主要目标(分类损失而不是均方误差)以及它更简单的界面,该界面允许用户键入一个表达式,该表达式根据常见的统计数据来定义g(q )(例如假阴性率或假阳性率,假定所保护的属性(这里是性别)具有特定的值)、常数、运算符(如加法、除法和绝对值)和统计数据,用户可以为其提供无偏估计,如回归示例中所示。我们使用图2中描述的数据集,将我们的分类算法应用于预测学生的平均绩点是否高于3.0,同时为分类约束五个流行的公平性定义(图3)。谢顿分类算法恰当地限制了所有试验中特定形式的不公平行为。与我们的方法不同,使用标准的最大似然方法设计的公平感知分类算法不能提供概率保证,即当应用于看不见的数据时,最终的分类器是可接受的公平的。我们观察到两种最先进的公平感知算法,我们运行的比较,公平学习(24)和公平约束(25),每一个都在至少一个公平定义下产生不公平行为。
接下来,我们使用我们的框架设计了一个通用的谢顿强化学习算法:一个不同于回归和分类算法的算法,它做出一系列相关的决策。在这种情况下,解决方案q被称为策略;历史H(随机变量)表示使用策略做出一系列决策的结果;可用数据D是由某个初始策略q0产生的一组历史。因为它是谢顿的,所以我们的算法在确保Pr(g(a(D)) le; 0) ge; 1 d的同时搜索最优策略。我们设计的算法与形式g(q)= E[r′(H)| Q0]E[r′(H)| q]的g兼容,其中用户选择r′(H)来测量a关于历史H有多不理想的特殊定义。也就是说,在概率至少为1 d的情况下,该算法不会输出增加用户指定的不良行为度量的策略q。请注意,用户只需要能够识别不良行为来定义r′;用户不需要知道由于应用不同策略而导致的历史分布。例如,如果不期望的行为发生在H中,用户可以定义r′(H)= 1,否则r′(H)= 0。
一些先前的强化学习方法保证以高概率增加主要目标(2628)。这些算法可以被视为谢顿算法或准谢顿算法,这些算法被限制为只对不理想行为的一个定义起作用:主要目标的降低。不合意行为的这种限制性定义排除了它们在不合意行为与主要目标不完全一致的问题中的应用(参见图S31的例子,其中行为约束和主要目标是冲突的)。类似地,数据驱动的稳健优化(29)也为约束sat-is action提供了高概率保证,但仅针对凸约束和不包括我们考虑的回归、分类和强化学习示例的目标f子集(14)。
在已经提出的强化学习的许多高风险、高回报的应用中,我们选择了一个来展示我们方法的可行性:自动调整1型糖尿病患者的治疗(30,31)。在本申请中,策略q(如上定义)是一个推注计算器,它确定一个人在摄入含碳水化合物的膳食之前应该注射的胰岛素量,以避免高血糖水平。为了模拟人类的新陈代谢,我们使用了一个详细的新陈代
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[235752],资料为PDF文档或Word文档,PDF文档可免费转换为Word

