
英语原文共 8 页,剩余内容已隐藏,支付完成后下载完整资料
基于实体、关系和文本推理的知识图谱嵌入技术
Binling Nie , Shouqian Sun
重点:
1. 能够进行更好推理的统一知识图谱结构
2. 用于多步路径建模的增强版LSTM的有效性
3. 注意力机制在多路径学习的作用
摘要:
在智能网络领域,知识图谱嵌入技术引起了广泛的研究兴趣,它旨在将关系和实体嵌入到低维空间。特别是,目前有两种截然不同的模型来进行知识推理:一种是隐特征模型,另一种是图特征模型。隐特征模型擅长于利用实体隐藏的特征去解释三元组和以及从数据中自动推知这些隐特征,而图特征模型则在从可见的图模式中抽取特征的方面表现得很好。结合这两种基础模型的优势是提高图模型预测性能的有效途径。因此,我们提出一个名为文本增强知识图谱嵌入的新组合模型,用来对实体、关系和文本进行推理。该模型不仅非常适合于对它们的隐特征之间关系进行建模,还适用于对图里面实体间路径进行建模。实验结果表明,该模型在知识图谱补全和三元组分类两个任务上,较基准线取得显著的进步。
1. 引言
知识图谱以实体和实体间的关系的形式对事实性信息进行建模,以此来语义化地表示世界的事实。最近,大量知识图谱被构建出来,如YAGO[1]、DBpedia[2]、NELL[3]、Freebase[4]还有谷歌知识图谱[5]。这激励我们去研究根据知识图谱中已存在的事实来推断新的关于世界的事实的统计模型。通常来说,现存的模型可以大致被分为截然不同的两类:隐特征模型和图特征模型。隐特征模型从隐特征的交互作用来获得实体间的关系,而如果三元组能从实体的邻里关系获得解释,或者从图中实体间的路径的知识推断中获得解释,则图特征模型的运算是高效的。这两种模型关注知识图谱的不同方面。实验证明,隐特征模型和基于图的模型通常是优势互补的[参考例如[6]]。所以,许多研究者将它们结合起来,以提高建模的能力[7-10]。[11]所提出的组合模型取得了目前最好的表现。
然而,之前的组合模型并没有完全发挥知识库的潜能,因为它们受到以下约束:(1)它们在预测新的事实时,仅仅考虑了关系而没有考虑构成路径节点的实体。而忽略实体往往会导致错误的发生。(2)它们只用一条路径作为对给定的实体对关系建模的依据。但正像图1所指出的,多路径能为预测提供更为科学的依据。(3)它们没有利用从文本语料库中抽取出来的文本关系来减少知识图谱的稀疏性。
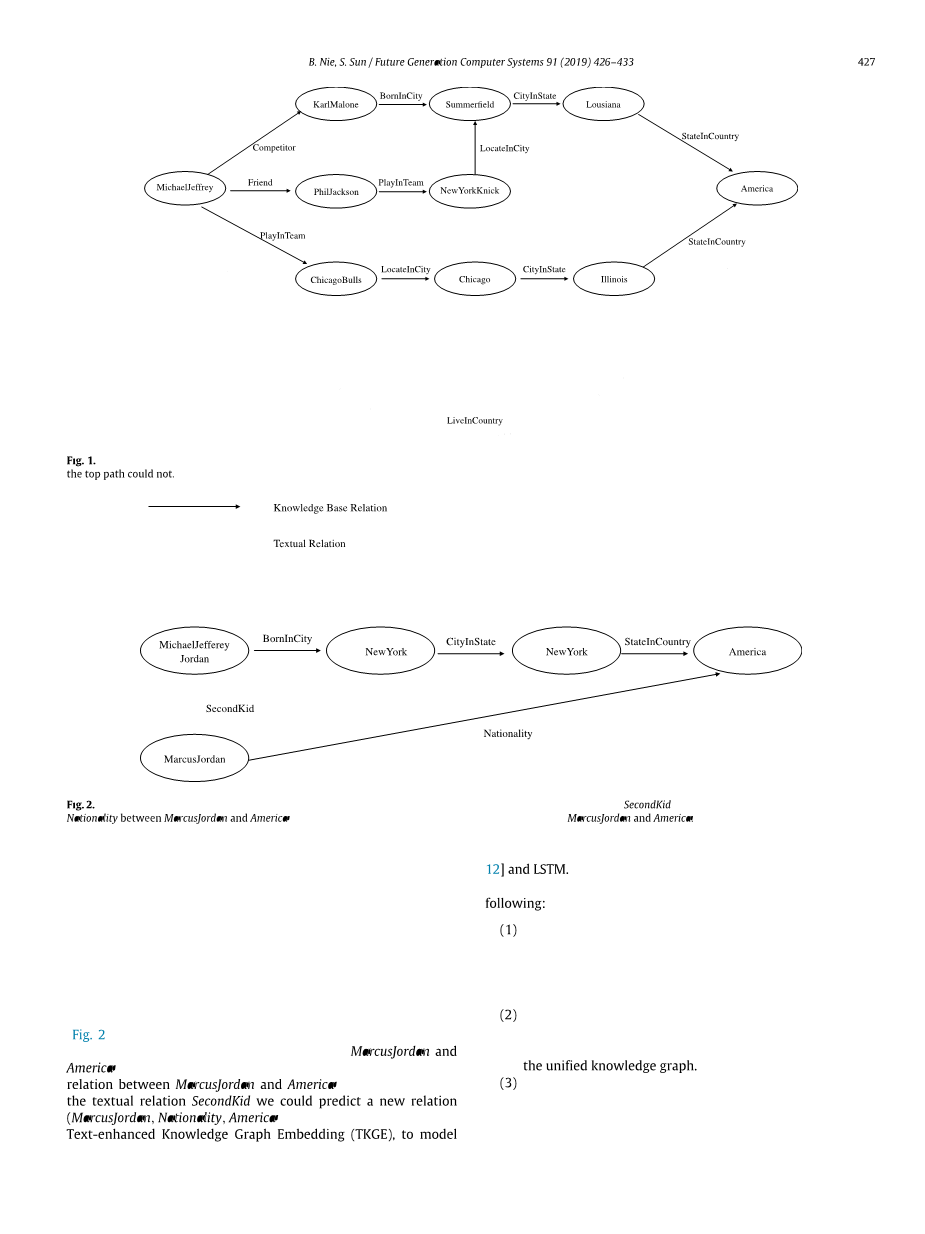
为了解决以上的问题,我们提出一种新的组合模型来从隐特征和可见的图形特征来学习知识图谱的映射向量。首先我们利用长短期记忆模型(LSTM)处理长期依赖的能力去对任意长度的路径进行有效的建模,并提出了一种增强型的LSTM,对给定的实体对的情况下,对一条多步路径的语义进行建模,这综合了将实体和关系展现在多步路径的优点。然后,我们整合了一种基于注意力机制的多对象学习方法,来学习一种(具有语义关系的)实体对间关联的详尽语义表示,该表示包含了给定实体间所有重要的路径的整体语义信息。而且,为了减少知识图谱的稀疏性,我们从巨大的语料库和一个用于推断的知识库构建了一副形式统一的图,并以此来补全知识库中没有链接的关系,并且充分利用丰富的关系知识推断文本信息来增强对形式统一图谱的知识推断。例如,如果图中的实体间没有路径相连,那就没办法推理出实体间存在任何语义关系。正如图2所示的那样,文本关系能够很好地解决这个问题。MarcusJordan和America之间没有直接的关系或是存在多步路径相连,所以不可能通过推理找到MarcusJordan和美国之间存在任何关系。然而通过利用“第二个孩子”这个语义关系,我们可以预测出一组新的关系(MarcusJordan, 国籍, 美国)。最后我们提出一个名为文本增强知识图谱嵌入(TKGE)的模型,来对统一的图中的隐特征和可见的模式进行建模。这种方法结合了典型的隐特征模型TransE[12]和LSTM的优势。
本论文的主要贡献总结如下:
(1) 我们提出了一个增强型的LSTM来为给定实体对间路径的语义进行建模,这综合了实体和实体间关系展现在路径中的优势,并且利用一种基于注意力机制的多对象学习方法来为给定实体对间的语义关系进行建模。
(2) 通过同时运行TransE和增强型的LSTM,我们的模型可以从统一图中的隐特征和可见的模式学习到更好知识图谱嵌入向量。
(3) 我们使用标准的数据集FreeBase和ClubWeb语料库对TKGE模型在知识图谱补全和三元组分类两种任务上的表现进行评估。实验结果表明,TKGE相较于两种任务的基准,取得了显著的提高。
本文的余下部分将按照以下顺序进行展开。第二部分简要地回顾相关的工作。第三部分详细的讲解我们提出的模型。第四部分,我们对数据集和实验设置进行说明。实验结果将在第五部分进行讨论,并得出本文的结论。
图1 在知识图谱中给定的实体对有多条路径。底部的两条路径给出了MJordan可能住在美国这一科学的事实,而顶端的路径却没有。
图2 说明语义关系能提高知识的连通性的例子。当MarcusJordan和美国之间没有直接的知识性事实时,利用语义关系第二个孩子,能推断出MarcusJordan和美国之间的新关系—国籍。
2. 相关的工作
2.1. 隐特征模型
隐特征通过实体的隐特征来解释三元组。RESCAL[13]是一个相关的隐特征模型,它通过隐特征的相互作用来解释元组,同时它通过张量分解来识别实体间的交互关系。多层感知机(MLPs)[10]提出创建复合三元组表示的其他方法,并且使用神经网络来预测它们的存在。它们通过矩阵来学习隐特征的相互作用。这显著降低了所需要参数的数量。神经张量网络是RESCAL方法的推广,它使用了MLPs的附加层。它可能需要很多的参数,因此在规模较小的数据集上往往会过拟合。另一类模型是隐距离模型,它通过实体的隐表示间的距离来得到存在关系的概率。文献[15]在利用任意的距离测度(如欧几里得距离)来对社交网络中存在关系的概率进行建模时首次提出这种方法。结构嵌入(SE)[16]将这个想法应用于知识图谱,它通过转换实体间的隐表示对关系进行建模。为了减少整个结构模型的参数的数目,TransE模型将隐特征表示转换为成关系的特定偏移。但这种简单的转换操作对1-N、N-1和N-N关系进行建模时,可能会出现问题。为了解决这个问题,TransR模型[17]将实体和关系理解为不同语义空间的对象。并在学习到实体间的潜在关系时,该模型将实体从实体空间投影到关系空间。[18]介绍了一种特定角色的投影,它将实体按照它在三元组中的角色映射到不同的向量中,并将其应用到TransE、TransH和TransR。[19]提出了一种新的知识图谱嵌入方法,它对头实体和尾实体进行双向映射。ProjE[20]通过学习知识图谱的实体和边的联合嵌入以及标准损失函数细微但却是重要的改变,来填补知识图谱中缺失的信息。[21]在极小极大博弈中通过对抗训练,统一了生成方法和识别方法。
2.2. 图特征模型
图特征模型直接将三元组解释为知识图谱中可见的三元组合。PageRank从图中的随机游走得到实体的相似性。Path Ranking算法(PRA)使用随机游走代替全局搜索,并且将在多关系知识图谱中,把独一无二的路径作为预测链接的特征值[22,23]。[24]使用递归神经网络来将任意长度的路径组成关系的语义,这样实体的相似度能被解释为语义的相似度。[25]扩展了递归神经网络以学习更高层次的知识图谱嵌入,从而在使用任意长度的路径时成功集成了对中间实体和关系建模的优点。[26]也高效地合并了知识库中所有有限长度的关系路径,同时将实体和关系建模于合成路径表示中。
2.3. 组合隐特征和图特征的模型
[7]提出了叠加关系效应(ARE),这是一种将隐特征模型与可视的图形模型相结合的方法。尤其是,将RESCAL与PRA的结合起来,使用的隐维度要低得多,从而加快了训练时间,并提高了准确性。除ARE之外,[27,28]还将一个隐特征模型与一个附加项结合起来,进而从多关系数据的潜在信息和基于邻域的信息进行学习。将这两个模型结合起来的另一种方法是分别对它们进行拟合,并使用一个模型的输出作为另一个模型的输入[10]。最近,[29]递归地使用隐特征模型来回答路径查询,探索从包含在短关系路径中的潜在和可观察的推理模式中进行学习,以规范实体向量的空间分布。[11]将TransE应用于通过潜在变量对全局关系模式进行建模,并利用简单对应元素加、乘或RNN等组合函数,通过关系路径上的知识推理得到可观察的图形模式。它们都取得了显著的进步,并且[11]保持着最好的性能。
3. 提出的方法
在本节中,我们将详细介绍我们如何对实体、关系和文本进行推理,以学习高级知识图形嵌入。
3.1. 符号
在本小节中,我们描述了本文中使用的符号。知识库(KB)由一组三元组T = {(h,r,t)}表示,每个三元组由两个实体h,t isin; E和一个关系r isin; R组成.E代表一组实体,r代表一组关系。有多个关系路径连接实体对(h,t)。我们在知识图谱中进行随机游走,得到从h到t的路径集p(h,t)=p1,hellip;,pn。让pi=(h,r1,e1,hellip;,ekminus;1,rk,t)。路径中的关系数是其长度,因此,(len(pi)=k)。当我们学习将实体和关系编码为d维向量(Rd)时,我们同等对待知识库关系和文本关系。
3.2. TKGE的架构
本文介绍了基于实体、关系和文本推理来进行知识表示学习的TKGE模型。受基于翻译的方法的启发,我们定义能量函数如下。
G(h,r,t)=E(h,r,t) E(h,r,t)(1)
其中,E(h,r,t)为直接关系三元组中的关系和实体之间的关联建模。p是指给定实体对(h,t)的多步路径的向量表示,称为语义关系。E(h,p,t)在语义关系三元组中建立了关系和实体之间的关联模型。如[11]所定义的,E(h,p,t)=E(p,r),描述了语义关系p与直接关系r的一致性,本文介绍了一种新的一致性评价方法,定义如下。
E(h,r,t)=E(p,r)=-log(P(p,r))(2)
其中p是语义关系,它包含给定实体对的所有路径的整体语义。P(p,r)描述了语义关系p和直接关系r的一致性,我们随后将详细介绍这一成分。
我们通过实体链接技术和开放信息提取系统为知识库关系和文本关系创建相同的节点。因此,我们从知识库和文本语料库中生成一个统一的知识图谱,并通过在统一的知识图谱中随机游动获得包含丰富推理模式的实体间多步关系路径。基于统一的知识图谱,TKGE的总体架构如图3所示。我们将经典的TransE原理应用于直接关系三重模型。在给定实体对的情况下,我们利用增强型LSTM对多步路径(语义关系)的向量表示进行建模,其中路径涉及实体和关系。通过计算语义关系与直接关系的一致性,建立了语义关系三元中关系与实体之间的关联模型。在模型中,我们学习了知识库关系和文本关系的向量表示。
图3 TKGE的总体架构
3.3. 路径排序算法
我们使用路径排序算法(PRA)[22]执行知识库推理,从源实体和目标实体中找到一组随机行走的路径,为一个关系提供了一组实体对的训练。PRA是一种在多关系知识图中区分训练的逻辑推理。PRA为知识库中的一对实体上生成一个特征矩阵,然后将包含这些实体对的路径分类为特定的关系类型,并找到将源实体连接到相应目标实体的路径,这些路径对于表示给定实体对的语义关系是有效的。然后,PRA计算实体对和路径类型的随机行走概率。我们不使用概率,因为它在我们的实验中没有取得良好的效果。此外,我们可以通过使用PRA得到任意长度的路径。
3.4. 路径的语义建模
长短期记忆(LSTM)[30]是一种增强型的递归神经网络。LSTM是为了解决在学习长期依赖关系时梯度消失问题而设计出来的。在记忆单元中,长时间保存信息实际上是它们的默认行为。LSTM具有神经网络重复单元链的形式。LSTM单元由输入门it、忘记门ft、输出门ot、存储单元ct和每次的步骤t的隐藏状态ht组成。这些门具有移除或添加信息到单元状态的能力。门向量it、ft和ot的分量是sigmoid神经网络层,其值在[0,1]中。介于0和1之间的数字,描述每个组件应被通过的程度。“0”表示“不让任何东西通过”,“1”表示“让所有东西通过”。以下是LSTM的转移方程:
it = sigma;(W(i)xt U(i)htminus;1 b(i))
ft = sigma;(W(f)xt U(f)htminus;1 b(f)
ot = sigma;(W(o)xt U(o)htminus;1 b(o)
ut = sigma;(W(u)xt U(u)htminus;1 b(u)
ct = it ⊙ u<su
全文共17288字,剩余内容已隐藏,支付完成后下载完整资料</su
资料编号:[2895]

