
英语原文共 20 页
用深度神经网络和树搜索来精通围棋游戏
作者:David Silver 1 , Aja Huang 1 , Chris J. Maddison 1 , Arthur Guez 1 , Laurent Sifre 1 , George van den Driessche 1 , Julian Schrittwieser 1 , Ioannis Antonoglou 1 , Veda Panneershelvam 1 , Marc Lanctot 1 , Sander Dieleman 1 , Dominik Grewe 1 , John Nham 2 , Nal Kalchbrenner 1 , Ilya Sutskever 2 , Timothy Lillicrap 1 , Madeleine Leach 1 , Koray Kavukcuoglu 1 , Thore Graepel 1 , Demis Hassabis 1
他们来自 Google DeepMind 英国团队(用1表示), Google 总部(用2表示) David Silver , Aja Huang是并列第一作者
目录
摘要
对于人工智能来说,围棋一直被视为最具挑战性的经典游戏,这是由于其巨大的搜索空间以及难于评估的棋盘盘面和走子。这里我们介绍了一个新方法:使用价值网络 (value networks )来评估棋盘盘面和使用策略网络 (policy networks )来选择走子。为了训练这些深度神经网络,我们将有监督学习(从人类职业比赛中学习)和增强学习(从自我对抗的比赛中学习)创新地结合在一起。在没有使用任何前瞻搜索的情况下,这些神经网络的水平已经相当于最先进的使用蒙特卡罗树搜索(MCTS:Monte Carlo tree search)的程序,这些程序模拟了成千上万的随机的自我对抗盘局。我们还提出了一种将蒙特卡罗仿真和价值网络以及策略网络结合起来的新搜索算法。使用该搜索算法后,AlphaGo 在和其他围棋程序的对弈中,赢了 99.8%的盘局,并且以 5 比 0 击败了欧洲围棋冠军。这是计算机程序首次在全尺寸的围棋对抗中击败职业围棋选手,这个壮举以前被认为是至少十年以后才会发生。
引言
具有完美信息的的游戏都有一个 最优值函数 v*(s), 它决定了在所有玩家完美发挥的情况下,从棋盘局势或 状态 s开始的比赛的结果。 这些游戏的解是在搜索树中递归计算最优值函数。搜索树包含约 bd个走子系列,其中 b是游戏的广度(每个状态下的合法走子数), d 是游戏深度(游戏长度)。对于大型游戏,如国际象棋 (basymp;35,dasymp;80),特别是围棋 (basymp;250,dasymp;150),穷尽搜索是不可行的。但有效搜索空间可以通过两个通用原则减少。首先,搜索的深度可以通过评估盘面减少:在盘面s截断搜索树,s下面的子树用能从盘面 s 预测结果的近似价值函数 v(s)asymp;v*(s) 代替。在国际象棋 4,跳棋,奥赛罗,该方法的表现超越人类,但是由于围棋的复杂性,该方法被认为是不可控的。第二,搜索的广度可以通过策略 p(a|s)的采样减少,p(a|s)是在盘面 s 的情况下,可能走子 a 的概率分布。比如 蒙特卡洛 rollouts搜索到最大深度,根本不走分支,它的实现就是通过策略 p来采样双方玩家的一系列走子。平均这样的rollouts 的结果可以提供有效的盘面评估。在西洋双陆棋和拼字游戏中,该方法的表现超越人类,在围棋上,达到了较弱的业余选手水平。
蒙特卡洛树搜索(MCTS:Monte-Carlo tree search)利用蒙特卡洛 rollouts 来评估每个盘面在搜索树中的值。运行越多的仿真,搜索树变得越大,相对值也越准确。用于在搜索过程选择动作的策略也随着时间推移而提高,该策略是通过选择有更高值的子树实现的。逐渐地,策略收敛到最优方案,评估也收敛到最优值函数。目前最强的围棋程序是基于MCTS 的,并通过训练成能预测专业选手的走子来得以加强。这些策略用于将搜索收窄到一束最有可能的动作,并在下棋时采样动作。该方法达到了很高的业余选手的水平。但是,这些以前的工作局限于肤浅的策略,或值函数是基于输入特征的线性组合。
近来,深度卷积神经网络(DCNN:deep convolutional networks)在视觉领域获得了前所未有的成功:比如,图片分类,人脸识别,雅达利游戏。DCNN 使用很多层的神经元,每层堆叠在一起,用于生成图片逐渐抽象的,局部的表征。我们也采样了类似的架构。将围棋棋盘上的盘面视为19x19的图片作为输入,然后通过卷积层来表征盘面。我们使用这些神经网络用于减少搜索树的深度和宽度:使用价值网络评估盘面,使用策略网络采样动作。
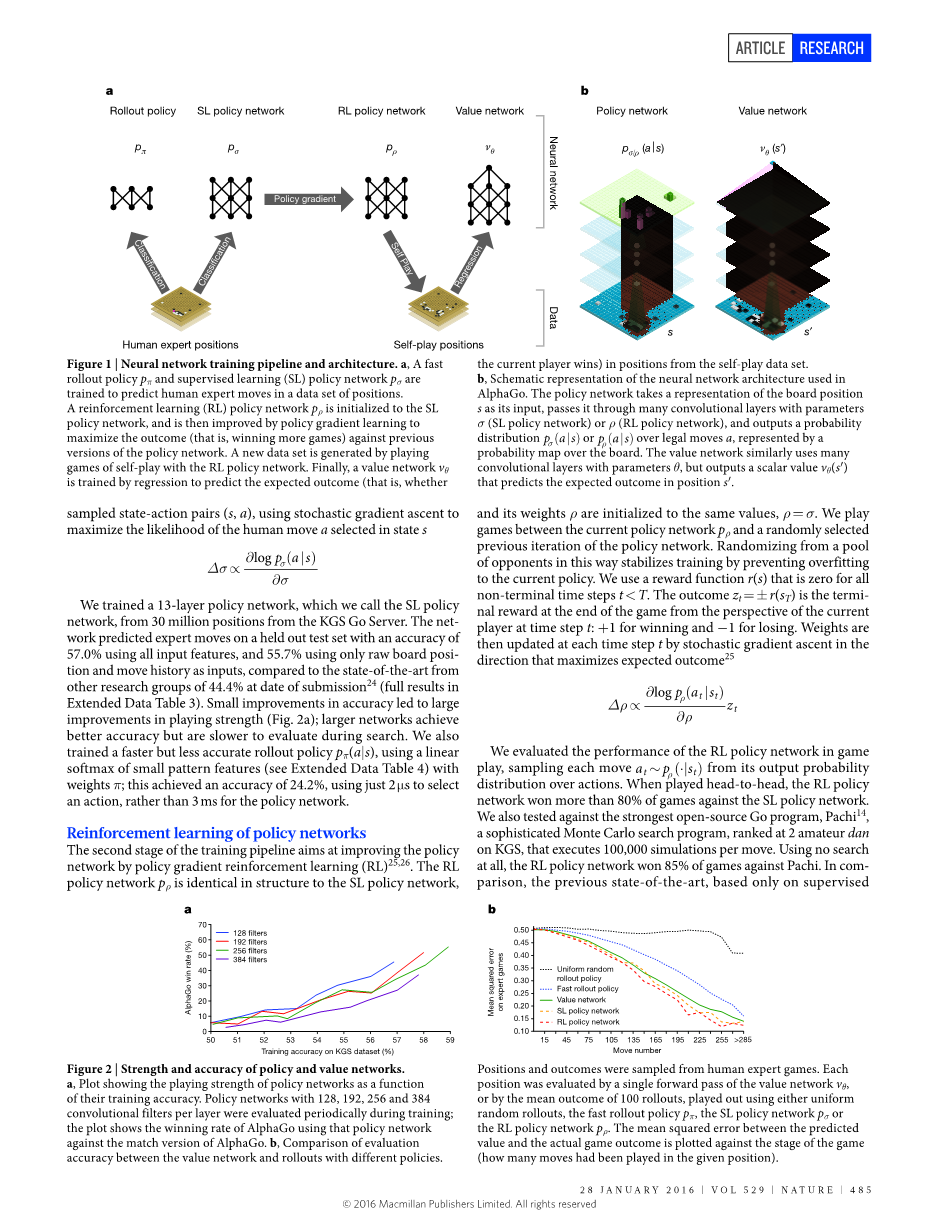
我们将几个机器学习的步骤串在一起来训练神经网络(图 1)。首先,我们训练了有监督学习(SL:supervised learning)策略网络 psigma; , 它直接学习专业选手的走子,该训练提供了快速有效的学习更新,并有立即的反馈,以及高质量的梯度。和以前的工作类似,我们也训练了一个可以在下棋时快速采样动作的快速网络 ppi;。然后,我们训练了增强学习 (RL:reinforcement learning)网络prho;,因为优化了自我对抗游戏中的最终结果,所以 能提高 SL 策略网络。RL 网络用于将策略调整为赢得胜利而非提高预测的准确率。最后,我 们训练了一个价值网络 vtheta;,用于预测 RL 策略网络自我对抗中的胜方。AlphaGo 将策略网络以及价值网络和MCTS有效地结合起来。
策略网络的监督学习
训练的第一步,我们是基于以前人们的工作,就是使用有监督学习来预测专业选手的走子。SL 策略网络 psigma;(a|s)的卷积层的权重为 sigma; ,采用 rectifier nonlinearities。最后的 softmax 层输出了所有合法动作 a 的概率分布。策略网络的输入 s 是棋盘盘面的简单表示(见扩展数据表 2)。该策略的训练基于随机采样的状态-行动对(s, a),使用随机梯度上升 法(stochastic gradient ascent)以最大化在状态 s 时人类选择走子 a 的似然度
我们使用KGS 服务器上的 3000 万个棋盘盘面来训练这个 13 层的 SL策略网络 , 使用held out 测试集,如果输入全部的特征,该网络预测专业选手走子的准确率是 57.7%,如果只输入棋盘盘面和走子
历史,预测的准确率是 55.7%。而其它研究人员达到的最新的最好成绩是 44.4%(全部结果见扩展数据表 3)。准确性的一点点提高都可以大大提高棋力(图 2a)。更大型的网络可以达到更好的准确性,但在搜索时的评估也会更慢。我们也训练了一个速度更快,但准确性也更低的 rollout 策略 ppi;(a|s),是小模式(small pattern)特征(见扩展数据表 4 ) 的线性 softmax,权重为 pi; 。 该策略的预测准确性是 24.2%,但只用 2mu;s就可以选择一个动作,而策略网络需要 3ms。
图1
图1:神经网络的训练流水线和架构。a: rollout 策略和有监督学习(SL)策略网络被训练来预测专业选手在盘面数据集里的走子。增强学习(RL)策略网络被初始化为 SL 策略网络,然后通过策略梯度学习以最大化和先前版本比赛的结果(比如赢得更多的比赛),这样提高了策略的水平。新的数据集的产生是通过 RL 策略网络的自我对抗比赛。最后,利用回归的方法训练价值网络,用来预测自我对抗数据集里的盘面可能导致的结果(比如当前玩家能否赢)。 b 这是 AlphaGo使用的神经网络 的架构的图示。策略网络使用棋盘盘面 s 的表征作为输入,通过许多的卷积层,卷积层的参数是 sigma; (SL策略网络) 或 rho; (RL策略网络),最后输出合法动作 a 的概率分布psigma;(a|s) 或 prho;(a|s),图上显示 的棋盘上的概率图。类似地,价值网络使用了许多的卷积层,参数为 theta;,但输出的是一个标量值 Vtheta; (s#39;),是盘面 s#39; 的预测结果。
图2
图2:策略网络和价值网络的战力和准确性。a 图上显示了策略网络的战力相对于训练后准确性的关系。具有 128,192,256 或 384 个积滤波器的策略网络在训练中被周期性地被评估,图上显示了使用策略网络的 AlphaGo 和比赛版本的 AlphaGo 比赛的赢率。b 价值网络和用不同策略进行下棋的评估准确性的比较。盘面和结果从人类专业比赛中采样。每个盘面只用价值网络 Vtheta; 评估一次,或用不同的策略各下 100 局后,然后平均各自的结果。这些策略包括完全随机(Uniform Random)走子 的策略,rollout 策略 ppi;,SL 策略网络 psigma;,RL 策略网络 prho;。预测结果和真实比赛结果的均方误差相对于盘面所处棋盘阶段(已经走了多少步)的关系已经画在了图上。
策略网络的强化学习
训练的第二步,目的是通过策略梯度增强学习(RL)来提高策略网络。在结构上,RL 策略网络 prho;和 SL 策略网络是一样的,它的权重 rho; 也被初始化为 SL 网络的值 rho; = sigma;。在训练时,我们让当前版本的策略网络 prho;和它的一个随机选择的先前版本相对抗。先前的版本组成一个对手池,从里随机选择可以让训练稳定下来,以防止当前策略的过拟合。对于非最后一步 tlt;T,回报函数(reward function)r(s)被定义为 0。从当前玩家在时间 t时的角度看,游戏的结果 zt = plusmn; r(sT)是游戏结束时最终回报: 1 代表赢了,-1 代表输了。然后使用随机梯度上升法(stochastic gradient ascent)在每一时间步骤 t 更新权重,以最大化期望的结果
我们评估了 RL 策略网络在比赛中的表现,走子的选择基于它输出的动作的概率分布。当 RL 策略网络和 SL 策略网络迎面对抗时,RL 策略网络赢得了 80%的棋局 。Pachi 是最强大的开源围棋程序,基于复杂的蒙特卡洛搜索,在 KGS 排名相当于业余 2 段,每一动作都需要执行 10 万次仿真。在完全不用搜索的情况下,RL 策略在和 Pachi 的对抗中,赢得了 85%的棋局。作为参照,以前最先进的只使用有监督学习的卷积网络,在和 Pachi 的对抗中,只赢得了 11%的棋局23,和稍微较弱的围棋程序 Fuego 的对抗中,只赢得了 12%。
价值网络的增强学习
训练的最后一步是棋盘盘面的评估。估计一个价值函数 vp(s),用来预测棋盘盘面 s 的结果,参赛的双方采用策略p
理想情况,是希望能得到完美比赛下的最优值函数 v*(s)。实际上,我们估计的是战力最强的 RL 策略网络 prho;的值函数vprho;。我们用权重为 theta; 的价值网络 vtheta;(s)来近似该值函数 vtheta;(s) asymp; vprho;(s) asymp; v*(s)。价值网络和策略网络的架构类似,但输出的是一个预测,而非概率分布。价值网络的权重是基于盘面-结果对(state-outcome pairs)(s,z)的回归来训练的,就是使用随机梯度下降法 (stochastic gradient d
资料编号:[4680]

