Speech Recognition
Victor Zue, Ron Cole, amp; Wayne Ward
MIT Laboratory for Computer Science, Cambridge, Massachusetts, USA
Oregon Graduate Institute of Science amp; Technology, Portland, Oregon, USA
Carnegie Mellon University, Pittsburgh, Pennsylvania, USA
1 Defining the Problem
Speech recognition is the process of converting an acoustic signal, captured by a microphone or a telephone, to a set of words. The recognized words can be the final results, as for applications such as commands amp; control, data entry, and document preparation. They can also serve as the input to further linguistic processing in order to achieve speech understanding, a subject covered in section.
Speech recognition systems can be characterized by many parameters, some of the more important of which are shown in Figure. An isolated-word speech recognition system requires that the speaker pause briefly between words, whereas a continuous speech recognition system does not. Spontaneous, or extemporaneously generated, speech contains disfluencies, and is much more difficult to recognize than speech read from script. Some systems require speaker enrollment---a user must provide samples of his or her speech before using them, whereas other systems are said to be speaker-independent, in that no enrollment is necessary. Some of the other parameters depend on the specific task. Recognition is generally more difficult when vocabularies are large or have many similar-sounding words. When speech is produced in a sequence of words, language models or artificial grammars are used to restrict the combination of words.
The simplest language model can be specified as a finite-state network, where the permissible words following each word are given explicitly. More general language models approximating natural language are specified in terms of a context-sensitive grammar.
One popular measure of the difficulty of the task, combining the vocabulary size and the language model, is perplexity, loosely defined as the geometric mean of the number of words that can follow a word after the language model has been applied (see section for a discussion of language modeling in general and perplexity in particular). Finally, there are some external parameters that can affect speech recognition system performance, including the characteristics of the environmental noise and the type and the placement of the microphone.
|
Parameters |
Range |
|
Speaking Mode |
Isolated words to continuous speech |
|
Speaking Style |
Read speech to spontaneous speech |
|
Enrollment |
Speaker-dependent to Speaker-independent |
|
Vocabulary |
Small(lt;20 words) to large(gt;20,000 words) |
|
Language Model |
Finite-state to context-sensitive |
|
Perplexity |
Small(lt;10) to large(gt;100) |
|
SNR |
High (gt;30 dB) to law (lt;10dB) |
|
Transducer |
Voice-cancelling microphone to telephone |
Table: Typical parameters used to characterize the capability of speech recognition systems
Speech recognition is a difficult problem, largely because of the many sources of variability associated with the signal. First, the acoustic realizations of phonemes, the smallest sound units of which words are composed, are highly dependent on the context in which they appear. These phonetic variabilities are exemplified by the acoustic differences of the phoneme,At word boundaries, contextual variations can be quite dramatic---making gas shortage sound like gash shortage in American English, and devo andare sound like devandare in Italian.
Second, acoustic variabilities can result from changes in the environment as well as in the position and characteristics of the transducer. Third, within-speaker variabilities can result from changes in the speaker#39;s physical and emotional state, speaking rate, or voice quality. Finally, differences in sociolinguistic background, dialect, and vocal tract size and shape can contribute to across-speaker variabilities.
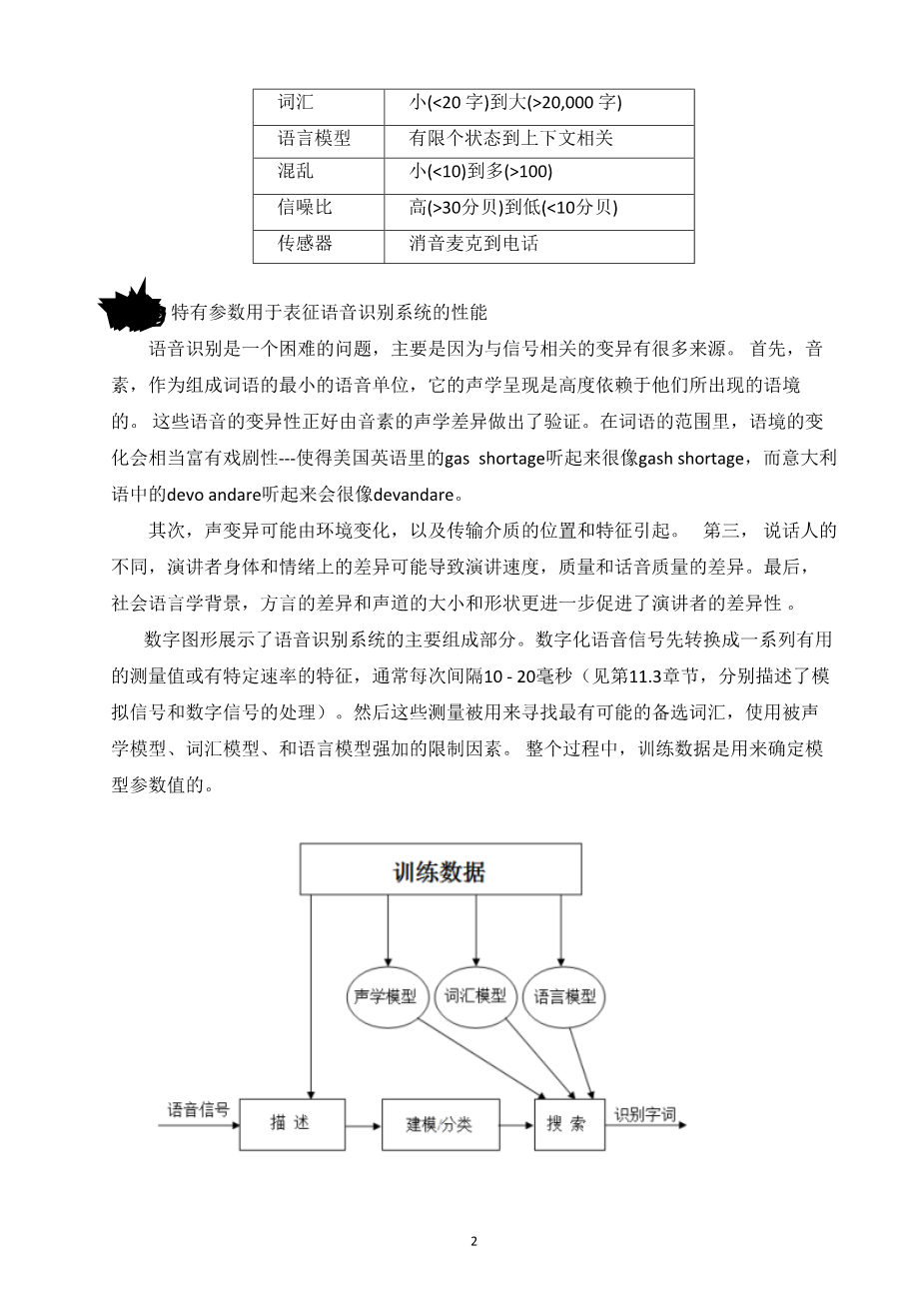
Figure shows the major components of a typical speech recognition system. The digitized speech signal is first transformed into a set of useful measurements or features at a fixed rate, typically once every 10--20 msec (see sectionsand 11.3 for signal representation and digital signal processing, respectively). These measurements are then used to search for the most likely word candidate, making use of constraints imposed by the acoustic, lexical, and language models. Throughout this process, training data are used to determine the values of the model parameters.
Figure: Components of a typical speech recognition system.
Speech recognition systems attempt to model the sources of variability described above in several ways. At the level of signal representation, researchers have developed representations that emphasize perceptually important speaker-independent features of the signal, and de-emphasize speaker-dependent characteristics. At the acoustic phonetic l
全文共16857字,剩余内容已隐藏,支付完成后下载完整资料

英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[15658],资料为PDF文档或Word文档,PDF文档可免费转换为Word

