
英语原文共 7 页,剩余内容已隐藏,支付完成后下载完整资料
一个企业级的音频搜索算法
摘要
我们设计实现并实际部署了一套灵活性很高的音频搜索引擎。核心算法抗噪声和扰动能力强,计算复杂度低,同时具有很高的可扩展性。即使外界噪音很强,它也可以迅速地通过手机录制的一小段压缩音频从百万级的曲库中辨识出正确的歌曲。算法分析音频频域上的星状图来组合时间-频率信息构造哈希。这种方式具有不寻常的优势,例如它能将混合在一起的几首歌都辨识出来。针对不同的应用,即使曲库非常非常大,检索速度也可以达到毫秒级。
1. 简介
Shazam公司创立于2000年,最初的目的是方便用户通过自己的手机检索正在播放的歌曲。(为了达到很高的可用性,算法必须具有下面几个特性。)算法必须能利用很短的音频片段辨识出正确的歌曲。特别地,即使该音频片段包含很强的噪音和扰动,并且经过各种损害性处理,例如压缩和网络丢包等,算法也需要准确地返回结果。此外,当曲库规模达到200万时算法也需要很快地返回结果。返回的结果在保证高识别率的同时必须具有很低的假阳性(false positive)概率。
这是一个很难的问题,到目前为止还没出现可以满足上述要求的算法,但是我们设计的算法可以满足上述要求[1]。
我们实际部署了一套曲库规模达180万的商用音乐识别服务。目前给德国、芬兰和英国的50w用户提供服务,很快就会覆盖欧洲、亚洲的多个国家以及美国。使用方法很简单:用户听到一首正在播放的歌曲,然后用手机录制15秒的片段上传到我们的服务器,服务器将歌手和歌名以短信的形式返回给用户。用户也可以通过网站访问我们的服务,并可以根据返回的歌名购买相应的CD或者自行下载对应歌曲。
目前有不少类似的应用: Musicwave公司采用philips算法[2-4]在西班牙部署了一套类似的系统。Neuros在他们的MP3播放器中内置了一个属性,允许用户截取30s正在播放的音频进行识别[5,6]。Audible Magic公司则采用Muscle Fish算法识别网络广播电台中的音频流[7-9]。
shazam算法除了辨识歌曲之外还有很多其他应用。由于算法抗噪能力强,例如,即使在广告中有很大的说话声,算法也能正确识别出其中的背景音乐。另一方面,由于算法非常快,还可以用来进行版权保护检测,速度可以达到1000倍实时。这样部署一台中型服务器就可以同时对多路音频流进行检测。shazam算法也适用于基于内容的跟踪和索引。
2. 算法的基本原理
数据库和录制的音频文件都需要提取可复现的哈希“令牌”,也即指纹。从未知音频中提取的指纹需要和音乐库中提取的海量指纹进行匹配。匹配上的指纹会用来衡量匹配的正确性。提取的指纹需要满足几个指导性原则:时间局部性(temporally localized),转换不变性(translation-invariant),鲁棒性(robust)和指纹信息量大(sufficiently entropic)。时间局部性表示指纹是由时间上接近的音频数据构造的,这样较远时刻的事件不会对该指纹产生影响(如果指纹是由时刻相距较远的音频数据构造的,则指纹会很不稳定,易受到外界噪音干扰)。转换不变性表示提取的指纹必须和位置无关,并且是可复现的。这是因为用户录音可以从任意位置开始。鲁棒性表示从“干净”音乐中提取的指纹也必须可以从含有各种噪音的音频中复现。此外,指纹也必须要包含足够的信息以便减少错误位置的无用匹配。指纹包含的信息量过少通常会导致冗余繁琐的匹配,从而浪费大量计算资源。但是,如果指纹包含的信息量过多又会导致指纹的脆弱性,使指纹在噪音和失真环境下不能复现。
shazam算法共有三个主要模块,下面分别进行介绍。
2.1 星状图
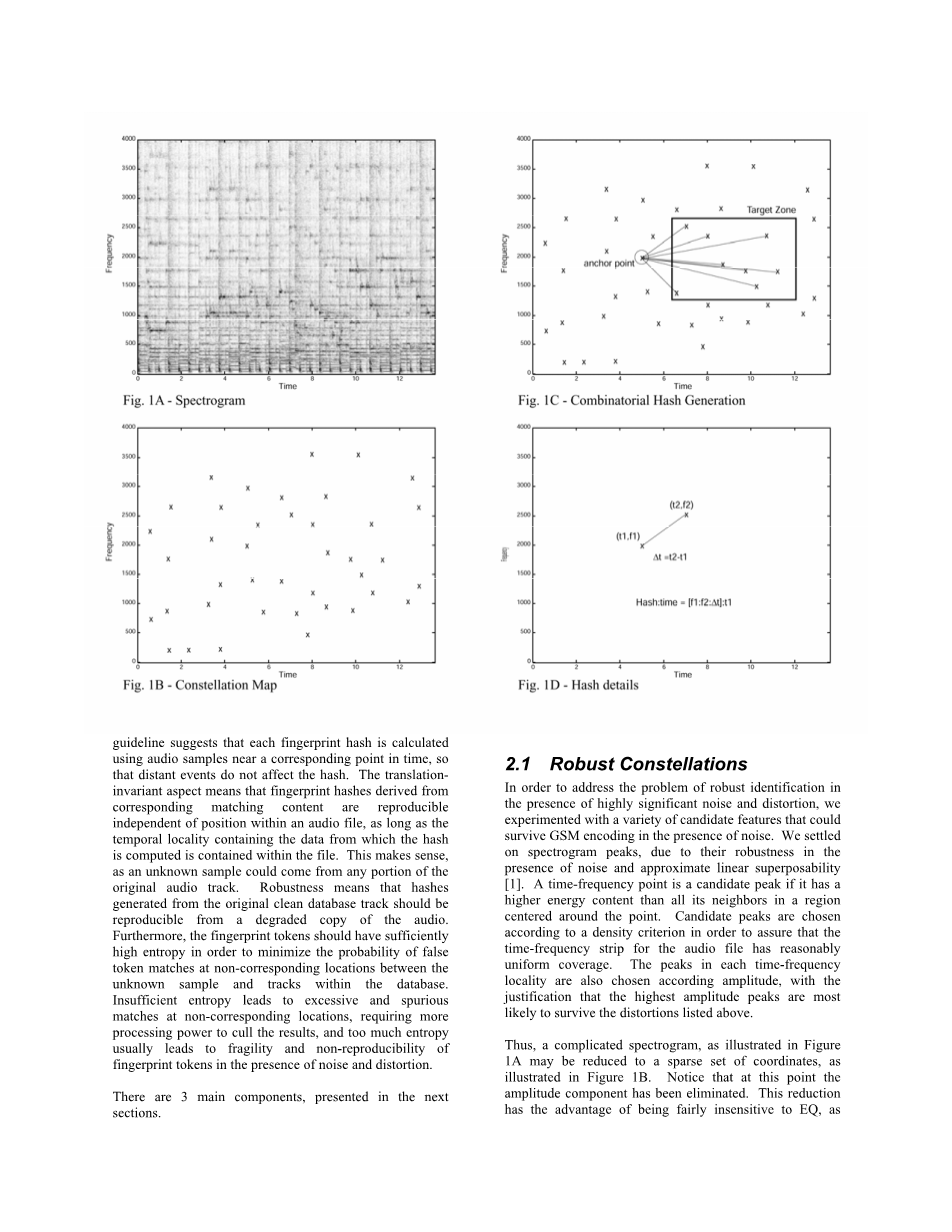
为了解决在噪音和失真情况下的音乐识别问题,我们尝试了大量的特征,最终选择了“频谱的极大值(spectrogram peaks)”。因为频谱极大值(亦可称为峰值)具有很强的抗噪能力,同时又具有近似的线性可加性[1]。频谱上的极大值表示在给定的时频区域内某个点的值大于所有的邻居。在选择候选极大值时需要满足密度准则使选取的极大值在不同的时间段内能均匀分布。在一个小的时间区间内选择极大值也要保证选择是最大值的极大值,因为最大值才最有可能在各种噪音和失真环境下保持不变(即最大值能在录音前后保持不变,也就满足指纹的健壮性)。
通过极大值选取,复杂的频谱图(1A)就简化成了稀疏的极大值坐标(1B)。需要注意一点,经过该步骤之后频谱图中的幅值信息就丢失了(只利用时间和频率信息,不利用幅值信息)。这种简化操作具有对EQ(不清楚怎么翻译)不敏感的好处。因为一个极大值经过各种滤波之后依旧会是相同位置的极大值(假定滤波器传递函数的导数很小,也即信号剧烈变化位置的峰值在经过传递函数之后只会引起轻微的频率上下浮动)。我们将这些稀疏的坐标称为“星状图”,因为它们确实很像天空中的星星。
在要匹配的样本中也会存在相同的星状图。如果将数据库中某首歌的星状图散乱在一个条形图上,然后将几秒样本的星状图放在一个透明的塑料板上。在条形图上滑行塑料板(有点像游标卡尺),到某个时刻的时候就会出现一件神奇的事情:当样本和数据库歌曲的正确位置对齐时,重叠的极大值就会格外多,这样就意味着样本和数据库中正确音乐的正确位置匹配上了!
即使噪音导致样本中存在很多虚假的极大值,但是由于极大值的位置都是相对独立的,所以重叠的极大值点个数依旧非常多。另一方面,如果很多正确的极大值被删掉了,也不影响重叠点的个数很多这个结论。所以星状图是噪音环境下音乐识别的一个利器,即使存在很多的虚假特征或者删除了过多的正确特征,星状图都具有很好的鲁棒性。通过星状图的使用,我们就将音乐识别问题简化为一个“星际航行”问题,在该问题中我们需要根据一小段”时间-频率”星状图快速定位它在长度可达10亿秒的条形图中的位置。Yang也考虑使用频谱峰值作为特征进行音乐识别,但是采用了不同的方式[10]。
2.2 快速组合哈希
如果直接利用星状图来计算正确的偏移会非常缓慢,因为单个时频点包含的信息量很少。例如,频率轴长度为1024时每个峰值至多产生10bit的频率信息(这就意味着相同频率的峰值会非常多,从而影响匹配速度)。我们实现了一种快速索引星状图的方法。
索引的核心是将两个时频点组合在一起构成一个指纹哈希。首先选择锚点(anchor point),每个锚点都对应一个目标区域(target zone)。每一个锚点都按序和目标区域中的点进行组合,组合的结果是两个频率加一个时间差(图1C和图1D所示)。这种方式产生的组合哈希具有很高的可复现性,即使噪音很强或者音频进行过压缩处理。此外,每一个指纹都可以存入一个int中(位数小于32)。每一个指纹都伴随有一个从文件开头到该锚点的时间差,所以绝对时间不包含在指纹中(指纹中包含的时间差是两个时频点的时间差,是一个相对值;绝对的时间差作为伴随属性存在)。
构造整个数据库索引的过程就是在每首歌上执行上述构造步骤,从而产生一系列的指纹和对应的绝对时间差。歌曲ID也会添加到这个紧凑的数据结构中,生成一个64bit的结构体,其中32bit存储哈希值,32bit存储时间差和歌曲ID。为了进行快速匹配,该结构根据哈希值排序(可以理解为用高32位的哈希值对上述结构进行排序)。
每秒产生的哈希个数约等于星状图的密度乘以目标区域的外联系数(fan-out factor)(含义是星状图的每个点都要和目标区域中固定个数的点连接形成指纹)。例如,每个时频点都是一个锚点,目标区域的外联系数F是10,则生成的哈希个数约等于10倍的时频点个数。通过限制外联系数,我们就可以限制最终生成指纹的个数。实际上,外联系数可以用来衡量存储空间的耗费程度。
通过组合哈希来代替单个时频点的匹配会带来巨大的性能提升。假设频率轴为10bit,时间差也为10bit,则组合哈希会产生一个30bit信息量的指纹。与原始的匹配相比多出了20bit,从而使哈希空间增大了100万倍,匹配速度也相应地加快(这是因为匹配时产生的碰撞更少了)。另一方面,组合哈希也会增大指纹的个数,数据库中会增大F倍,检索的时候样本构造的指纹也会增大F倍,从而采用组合哈希最终获得的加速比为1000000/F2,大约为10000倍。
(组合哈希也并非没有坏处),它会使某个点存活的概率由p变为p2(就是概率变小)。假定p是频率极大值点在原始信号和录制音频中都存在的概率,组合哈希也包含该极大值点的概率就为p2。速度的提升是以概率的降低为代价的。但是可以通过外联系数来减小概率的降低。假定F=10,则某个锚点至少存活一个哈希的概率等于该锚点与其目标区域中至少有一个组合哈希存活的概率。如果我们将目标区域中的点认为是独立的,则某锚点至少有一个组合哈希存活的概率为。对于很大的F(Fgt;10)和合理的p(pgt;0.2),会存在
所以,组合哈希加外联系数不会导致检索准确率的大幅下降。
可以看出,通过采用组合哈希,我们用10倍的空间获得了10000倍的性能提升和轻微的准确率下降。
我们可以根据信号源的噪音情况来决定外联系数大小和星状图的密度。比较干净的音频,比如广播监控,F值就可以选取得较小,星状图密度也可以很低(在该应用中,可以直接截取广播流,没有环境噪音)。针对噪音很大的手机录音,F值和星状图密度就需要适当大点。不同环境之间可能会产生几个数量级的差异。
2.3 检索和打分
在执行搜索之前,需要先从录音样本中提取所有的哈希值和时间偏移信息。样本中提取的哈希都会用来和数据库中的哈希进行匹配。每一个匹配的哈希会产生一个时间对:样本中的时间和数据库中的时间。根据对应的歌曲ID将时间对分类。
当样本中提取的指纹都完成上述匹配之后,扫描时间对获得正确的歌曲。每个歌曲对应的所有时间对构成了一个散点图,如果歌曲和样本匹配,则匹配上的特征会有相近的相对时间偏移,也即样本中提取的指纹和正确歌曲匹配上的指纹具有相同的相对时间(这个相对时间其实就是样本在原始歌曲中的起始位置)。这样就可以将搜索问题简化为散点图中寻找明显对角线的问题,该问题有很多现成的技术可以用,例如Hough变换或者其他回归技术。但是这些方法复杂度太高,同时对异常值比较敏感,所以不适用。
但是考虑到问题的特殊性,我们可以设计一个复杂度为N*logN的算法,其中N表示散点图中点的个数。不失一般性,假定对角线的斜率为1.0(录音速度和原曲速度一致,绝大多数情况都是如此),则样本和正确歌曲中匹配指纹的时间满足下面的关系式:
。
其中,表示原始歌曲中匹配指纹的时间,表示录音样本中对应指纹的时间。对于散点图中的每一个点(,),我们计算
然后我们计算的直方图并扫描获得直方图的最
大值(其实就是将时间对的两个时间相减,然后统计相同时间差个数的最大值)。求最大值可以通过扫描完成。由于组合哈希的原因,散点图通常会非常稀疏。同时每首歌对应的时间差个数通常很少,所以扫描过程会在几微秒之内完成。每首歌对应的得分也即直方图的最大值。如果直方图的最大值很大,那就意味着该首歌就是要识别的正确歌曲。图2A展示了一个错误匹配的例子,图3A展示了一个正确匹配的例子。图2B和图3B分别表示图2A和图3A对应的时间差直方图。对每一首歌的时间对都执行上面的计算直到找到一个很明显是正确的匹配。
需要注意的是上面介绍的匹配和扫描操作都没有对哈希的格式进行任何限制。实际上,哈希值只需要包含足够的信息量来避免虚假匹配同时又具有可复现性即可。在扫描阶段,只需要保证匹配的哈希在时间上对齐即可。
2.3.1 置信度
如上所述,匹配的得分是具有相同时间差的指纹个数。在确定算法false positive的过程中,错误歌曲的得分分布也很重要。简单概括一下,统计所有错误歌曲的得分获得一个错误得分直方图,同时根据数据库中歌曲的数目生成一个错误得分的概率密度函数。我们之后就可以根据这个函数来设定可接受的false positive(根据不同的应用falsepositive可以设置为0.1%或者0.01%)。
3 性能
3.1 抗噪性
算法在噪音很强或者非线性失真的情况下都表现良好,说话声、汽车声、片段丢失甚至其他正在播放的音乐都不影响最终的识别结果。利用shazam算法,一段被破坏严重的15s片段也可以通过1~2%存活的哈希获得置信度非常高的匹配。通过统计直方图的时间差个数作为匹配结果有一个优势就是它对音频是否连续不敏感,这样即使存在片段丢失或者信号掩蔽都不影响最终的匹配结果。一个更令人惊讶的结果是,即使在一个很大的数据库中,我们也可以正确识别出混合在一起包含有重复片段的多首歌,我们将算法的这个特性称为(其他音乐对正在识别音乐具有)“透明性”。
图4表示不同长度和噪音情况下,对 250个片段进行10000曲库规模检索的结果。为了模拟真实情况,噪音样本是从嘈杂的酒吧录制的。音频片段长度分别为15s,10s和5s,而且都包含在10000首歌中,添加的噪音也都是标准化之后的。可以看出,当15s,10s和5s片段的信噪比约为-9,-6和-3dB时,识别准确率降低到50%。图5对进行过GSM6.10压缩之后转成PCM格式的音频进行了同样的分析,可以看出,当15s,10s和5s片段的信噪比上升为-3,0和 4dB时,识别准确率降低到50%。
3.2 速度
对于一个包含有2w首歌的曲库,根据参数设置和具体应用的不同,检索速度在5到500毫秒之间。如果样本噪音较大,检索时间通常在几百
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[409976],资料为PDF文档或Word文档,PDF文档可免费转换为Word

