
英语原文共 27 页,剩余内容已隐藏,支付完成后下载完整资料
高污染城市室内细颗粒物浓度森林随机回归与多元线性回归预测评价
背景:室内和室外的细颗粒物(PM2.5)都是导致死亡和疾病的主要危险因素,但对大量人群进行室内测量和研究通常是不可行的。
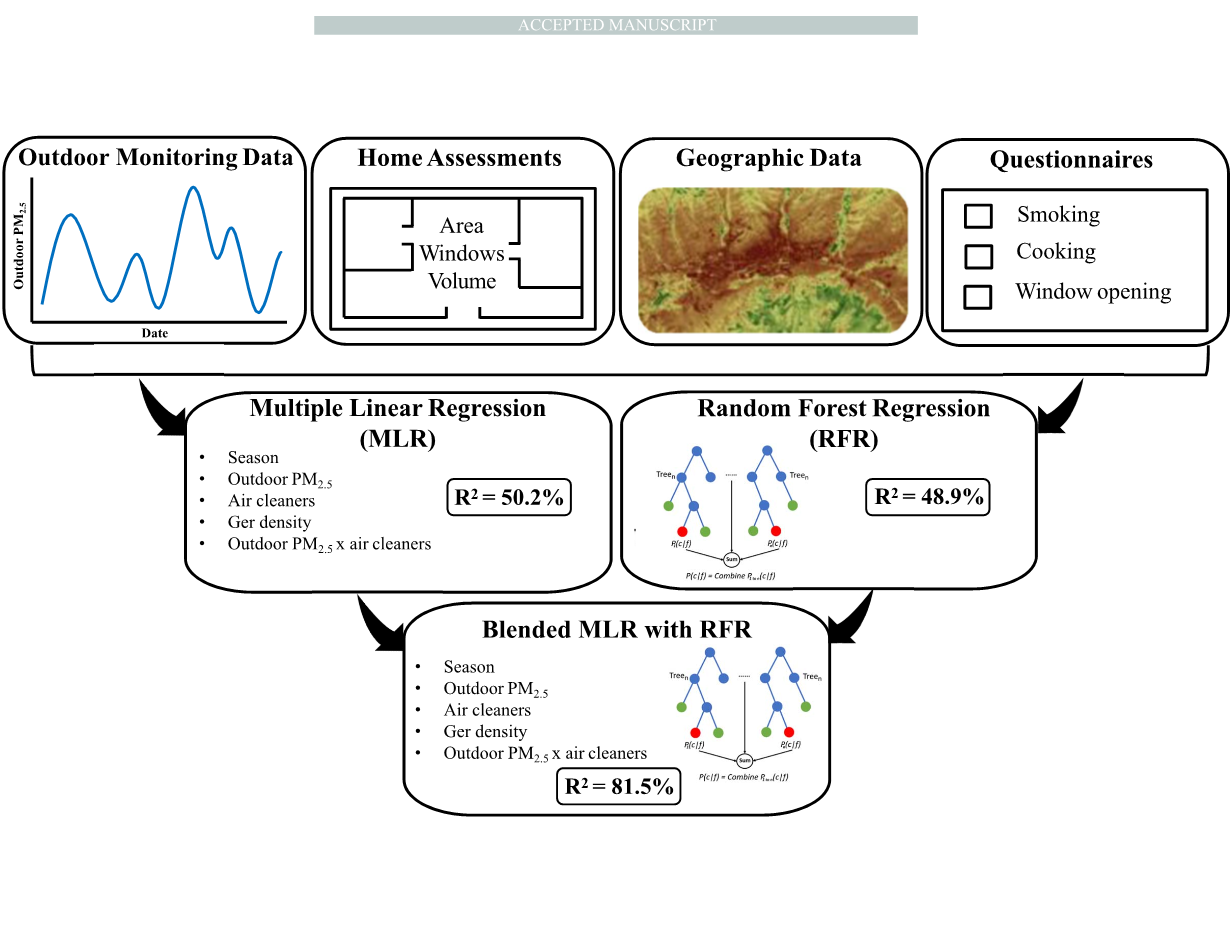
采用多元线性回归(MLR)和随机森林回归(RFR)对447个独立7天的室内PM2.5浓度进行建模。
方法:我们建立了孕妇室内PM2.5浓度的预测模型,这些孕妇是随机对照试验的一部分,他们在蒙古乌兰巴托室内有便携式空气净化器。
从户外监测数据、问卷调查、家庭评估和地理数据集中获得的PM2.5测量值和87个潜在预测变量。我们还开发了结合MLR和RFR方法的混合模型。所有模型均以10倍交叉验证进行评估。
结果:MLR模型的预测因子为季节、室外PM2.5浓度、配置的空气净化器数量以及公寓周围的蒙古包(传统毛毡衬里蒙古包)密度。MLR和RFR在交叉验证中表现相似(r2=50.2%,r2=48.9%)。包含RFR预测的混合MLR模型具有最佳性能(交叉验证r2=81.5%)。仅干预状态就解释了室内PM2.5浓度变化的6.0%。
结论:我们使用容易获得的预测变量预测了室内PM2.5浓度的中度变化,模型解释了比单独干预状态更大的变化。虽然RFR显示了模拟室内浓度的前景,但我们的结果强调了评估模型性能时样品外验证的重要性。我们还证明了混合MLR/RFR模型在预测室内空气污染方面的改进性能。
简述
据我们所知,这是第一次应用和评估随机森林回归和混合模型模拟室内空气污染浓度,这些技术在公开估计健康风险评估和流行病学中崭露头角。
介绍
接触评估在大气污染流行病学和风险评估中起着至关重要的作用。因为大多数人80%以上的时间是在室内度过的,所以室内的污染浓度是个人总暴露量的一个重要决定因素(1,2)。
室内浓度是由室内产生的污染和渗入室内的超标污染造成的(3)。如果研究人员能够在所有时间和地点量化每个研究参与者的暴露量,这将是一个理想的选择,但是在大型队列或长期(4-6)中,直接测量室内浓度和/或个人暴露量通常是不可行的。因此,建模已被用于克服室内和个人测量的财务和后勤限制,使研究人员能够在无法直接测量的情况下预测浓度(6)。
近年来,室内空气质量建模研究采用了多元线性回归(MLR)等统计回归方法。这些经验方法相对容易应用,因为有关影响室内污染物浓度的大多数变量的信息可以通过问卷或现有数据库收集。反过来,这可能使研究人员能够对大量人口进行预测。
一个有希望替代MLR的是应用机器学习技术,如随机森林回归(RFR)。RFR是一种基于分类或回归技术的集成学习方法(取决于因变量的类别),其使用决策树(7)。这是一种目标分割技术,它迭代地将输入数据(称为节点)分割为两个或多个数据样本(称为子节点)。这种递归分区将继续进行,直到满足某些特定的条件,例如,当连续拆分不能产生明显的改进,或者子节点中的变化变得太小(8、9)时。在RFR中,每个节点被分成两个或多个子节点,使用在该节点随机选择的预测子集中的最佳值。每个子节点中的数据用于预测该节点中因变量的值。然后将所有子节点的结果组合起来生成最终预测(8-10)。
与MLR不同,RFR不需要数据分布假设,并且在建模过程中,不需要建模者指定这些术语,RFR就可以检测预测器之间的交互作用和更高阶关系。然而,有人批评RFR是一个“黑匣子”,它可以产生很难解释的高度预测模型(11)。此外,对于具有不同水平数的独立分类变量,RFR的变量重要性分数不可靠,因为该方法偏向于具有更多水平的变量(9,12-14)。
目前尚不清楚哪种建模方法能更好地预测室内细颗粒物(PM2.5)的浓度。因此,我们利用MLR和RFR技术模拟了蒙古首都乌兰巴托孕妇公寓中PM2.5的浓度。乌兰巴托的空气污染浓度是世界上最高的(15)。空气污染的主要来源是城市中心(16)周围的蒙古包(传统毡衬蒙古包)的家用加热炉产生的煤烟。我们保守估计,乌兰巴托近10%的死亡率可归因于环境空气污染(15)。该分析的目的是:1)利用MLR和RFR建立每周室内PM2.5浓度预测模型;2)评估和比较MLR和RFR模型的性能;3)探索结合MLR和RFR方法的混合模型。
方法
研究设计和人口
我们的研究使用收集的数据作为乌兰巴托人的妊娠和空气研究(ugaar)研究的一部分。这项随机对照试验的目的是评价高效微粒空气(HEPA)过滤器的使用对妊娠、胎儿生长和儿童早期发育的影响。UGAAR研究设计已在前面描述过(17)。简言之,我们招募了540名符合以下标准的妇女:18岁或以上;在单胎妊娠的早期阶段(le;18周);不吸烟;住在公寓;计划在乌兰巴托的一家妇产医院分娩;入学时不在公寓内使用空气清洁器。我们排除了居住在蒙古包的妇女,因为我们有兴趣评估社区水平的空气污染对室内居民PM2.5浓度的影响,并希望尽量减少蒙古包炉具室内排放的影响。此外,许多蒙古包家庭缺乏可靠的电源,这是操作空气滤清器所必需的。分配给干预组(n=268)的妇女,从登记到分娩,她们被给予一到两个高效空气过滤器空气清洁器(取决于公寓大小)用于她们的公寓。对照组参与者(n=272)未收到空气净化器。28名受试者失去了随访机会,留下512名受试者(干预组259名,对照组253名)随访至妊娠末期(表1)。
数据采集
从2014年1月到2015年12月,共收集了98份数据。研究人员在参与者入组后不久(平均妊娠期为10.5周)和大约30周时再次访问了每位参与者的公寓。在干预组的第一次家访中部署了高效空气过滤器空气清洁器(Coway AP-1009CH),并一直运行到参与者出产后。参与者们使用的空气滤清器经过改装,只能在第二高的风扇设置下工作。在两次访问中,现场技术人员都部署了空气污染监测设备,七天后又将其取回。技术人员还完成了公寓评估,并在两次家访期间使用全球定位系统(GPS)获得了公寓位置。大约在家访的同一时间,研究人员在门诊访问时进行问卷调查,以获取有关住房特征、室内污染源和居民行为等信息。
数据源
使用Dylos DC1700激光粒子计数器(美国加利福尼亚州里尔斯公司)测量室内PM2.5浓度。Dylos的性能已通过与城市和农村环境(18-21)中的多个传统重量式PM2.5监测装置的对比进行了验证,认可度一直很高,尤其是在室内(R2:86-90%,补充材料表1)。在UGAAR研究中对Dylos单元进行了一些细微的改动,其他细节在补充材料第1节中进行了描述。我们在分析前(17)对粒子数数据进行了一系列质量控制和数据清理步骤,从342套公寓中留下447个7天的测量数据进行分析(表1)。与整个队列相比,具有至少一个用于模型开发的有效Dylos测量值的参与者更可能在夏季被招募,而在春季或秋季被招募的可能性较小(表1)(17)。哈佛个人环境监测仪(美国缅因州哈里森,空气诊断与工程公司,HPEMS)与Dylos装置一起,在同一个7天的时间内部署在公寓的便利样本中,以估计Dylos粒子数和基于过滤器的PM2.5浓度之间的关系。我们发现了很强的一致性(r2=94.2%,n=22,补充材料图1),并使用这种关系将Dylos粒子数转换为PM2.5质量浓度(17)。
2013年6月1日至2015年12月31日期间的室外PM2.5测量从两个政府运行的测量站获得(补充材料第2节)。我们还计算了每个参与者的公寓和两个车站之间的距离,然后在离每个住宅最近的车站分配室外PM2.5测量站(补充材料表2)。
从两个政府运行的监测点获取温度和风速数据。由于另一个监测站的大量数据丢失,我们使用了单个监测站的温度。我们还采用了先前发布的方法来创建风停滞指数(22)(补充材料第3节)。考虑到室外PM2.5(15)的季节性变化,季节也被视为室内PM2.5的潜在预测因素(补充材料表2)。
除了干预状态,我们还根据为每个参与者部署的空气滤清器数量创建了一个新变量。还计算了干预组参与者的空气滤清器密度(每平方米室内面积的空气滤清器数量)(补充材料表2)。我们试图从两个方面评估空气滤清器的使用情况。ugaar使用的空气滤清器经过内部计时器的修改,该计时器计算了使用总小时数。不幸的是,每次打开空气滤清器时,内部计时器都需要特定的程序来启动,而这通常不会发生。当参与者在不启动计时器的情况下使用空气滤清器时,随后的空气滤清器使用时间不会被记录下来。因此,在模型开发中没有使用计时器数据。此外,晚期妊娠调查问卷询问参与者:“既然我们把它/他们放在你家里,空气清洁器运行的时间百分比是多少?”“一些参与者未能对这个问题(17)作出回应,因此在模型开发中也没有使用它。
问卷导出的变量一般分为三类:住房特征(例如,建筑物的年龄);居民和行为(例如,公寓内的吸烟者人数);以及使用非提供的空气清洁器作为ugaar干预措施。技术人员还计算了每个公寓每个房间的窗户数量,并测量了它们的尺寸。根据测量尺寸(补充材料表2)计算室内总面积和体积。加热和烹饪不作为潜在的预测因素,因为这些变量几乎没有变化。除了六名拥有有效Dylos数据的参与者外,其他所有参与者都有同一家发电厂提供的中央供暖设备,除了12位参与者以外都是用电烹饪的。
模型中总共考虑了58个潜在的预测空间变量(补充材料表2)。我们之前使用高分辨率航空照片、谷歌地图图像和卫星图像分别生成了GER位置、道路位置和土地覆盖变量(亮度、绿色、湿度)的空间数据(16)。这些数据被用作每个参与者住所周围圆形缓冲区空气污染排放的代理。这些缓冲器的半径从100到5000米不等,以解释城市不同来源的不同分散模式。此外,我们使用数字海拔模型(23)中的海拔作为潜在预测因子。最后,我们还将冬季NO2(交通排放指标)和SO2(煤炭燃烧指标)浓度纳入使用2010年测量数据(15)开发的土地利用回归模型中。
最终数据集共有447个PM2.5观测值,87个潜在预测变量可用于模型构建(补充材料表2)。将自然对数变换应用于实测的室内PM2.5,以获得MLR和RFR模型的近似正态分布。
MLR建模过程
我们开发了一个主要的MLR模型,然后测试了三个可选变量选择程序。在主MLR模型中,我们采用了一种模型建立程序,该程序已用于开发户外污染浓度的土地利用回归模型(24,25)。
(a)首先,我们确定了一些变量,这些变量是我们预期的一个先验变量,可以修正污染排放(室外或室内)和室内PM2.5浓度之间的关系。这些包括干预状态、室外温度和典型的开窗行为。
(b)我们对87个预测变量的对数转换室内PM2.5值进行回归,没有任何分层(整体),并且根据步骤(a)中确定的变量进行分层。
(c)然后根据步骤(b)提取每个变量的p值。与对数转换室内PM2.5值(p值gt;0.05)总体或任何地层中无显著相关性的变量从进一步分析中删除。
(d)其余预测因子分为15个子类:1)干预、2)季节、3)开窗行为、4)空气滤清器使用、5)室内污染源、6)室外PM2.5浓度、7)其他室外污染(NO2、SO2)、8)温度、9)风阻、10)亮度、11)绿色、12)湿度、13)GER密度、14)道路长度和15)海拔。
(e)在具有多个预测因子的类别中,采用对数转换室内PM2.5确定了具有最高确定系数(r2)的预测因子。
(f)从进一步分析中剔除了与类别中排名最高的预测因子高度相关(连续预测因子之间rgt;0.6)或相关(分类预测因子之间卡方检验的p值lt;0.05)的预测因子。
(g)其余预测因子根据非分层(整体)确定系数(r2,从高到低)进行排名。然后将每个预测因子按顺序输入回归模型。只有显著的预测因子(plt;0.05)的部分r2大于1%,并且与先验假设一致的系数(如室外PM2.5的正系数)被保留。
(h)UGAAR研究是基于室内空气净化器能够降低室外PM2.5对室内PM2.5浓度的影响的假设而设计的。因此,也考虑了室外PM2.5与空气净化器配置数量之间的相互作用项。还考虑了其他三个可能的相互作用项(1月份的温度x典型开窗行为,1月份的室外PM2.5 x典型开窗行为,以及季节x干预)。如果交互作用项具有统计学意义(plt;0.05),并且没有使其他预测因子(步骤g)无关紧要,并且改善了模型性能,则将交互作用项纳入模型中。
数据集中有来自个人住宅的重复测量(342套公寓的447次测量)。在生成主MLR模型后,通过重新运行一个带有随机家庭截获的混合模型来评估在同一公寓中进行的测量之间可能的相关性,以确保所有保留的预测因子以类似的方式运行。我们评估了MLR模型假设的有效性、多重共线性的存在以及影响观察结果的影响。为了进一步探索季节作为某些预测因子的可能影响修正因子,我们还为供暖和非供暖季节开发了单独的模型,分别定义为平均室外温度小于等于10℃和大于10℃的7天时段。
我们开发了三个额外的MLR模型来探索其他变量选择程序:(1)最小绝对收缩和选择算子(lasso)方法;(2)一个模型,其中所有预测变量在一级模型建立后都保持不变,目的是最大化r2;(3)逐步(向后,Plt;0.05保持在模型中)变量选择。基于上述步骤(h)中描述的标准,所有MLR模型中都考虑了相同的相互作用项。
RFR建模程序
我们使用了一个从以前的工作(9)修改的RFR建模过程。原始输入数据由MLR建模过程中步骤(f)后的所有变量组成。我们从原始输入数据中选择了500个引导样本作为要生长的树的数量。根据每个引导样本的训练数据,生成回归树。在每个节点,随机抽取预测因子(我们使用默认值),并从这些变量中选择最佳分割。接下来,通过聚合预测来预测新数据。为了进行比较,我们还开发了使用100、1000和1500棵树的RFR模型。R版本3.3.2(26)的森林随机包装(27)用于开发RFR模型。未使用变量重要性分数。
混合建模过程
开发了三种混合模型,将MLR和RFR方法结合起来。首先,我们从主要的MLR和RFR模型中平均预
全文共6312字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[2930]

