
英语原文共 9 页,剩余内容已隐藏,支付完成后下载完整资料
基于HBase的矢量空间数据存储与访问优化
摘 要
为了对空间矢量数据进行高效存储、管理与发布,将分布式存储应用于地理信息系统( GIS) 的海量矢量空间数据管理。釆用网格法对地理空间进行划分,构建地理空间分块索引表,计算出每个网格单元对应的 ID; 同时为了提高查询效率,引入网格索引 ID,设计了一种结合网格索引 ID、空间对象几何中心点横坐标、空间对象几何中心点纵坐标、空间对象图层四种信息的行键方案; 然后,为了进一步筛选查询纵坐标范围的行键,利用 HBase 的过滤机制,在行键方案基础上,具体设计集空间对象几何中心坐标点纵坐标和图层信息的组合列族,使得 HBase 方便高效地管理矢量空间数据,大幅提高查询的处理速度。最后利用 Hbase 集群环境对所提方法进行验证,该方法具有较好的可行性和较高的效率。
关键词: 云计算; HBase; 行键; 过滤; 组合列族
引言
面对海量和复杂的空间矢量数据,如何对其进行高效存储、管理与发布,已成为一个迫切需要解决的问题。云计算是一种新的分布式计算架构,具有大规模扩展、水平分布的特性,可以提供无限的存储能力和计算能力。将分布式存储应用于地理信息系统( Geographic Information System,GIS) 领域是解决海量矢量空间数据管理问题的有效手段[1]。HBase 使用 Hadoop 的分布式文件系统( Hadoop Distributed File System, HDFS) 作为底层存储,是一个分布式、按列存储的数据库。 HDFS 适合于存储海量数据,但它设计是用于大吞吐量数据的,并且有一定的延时,不太适合吞吐量小且要求低延时的访问操作; HDFS 只能在文件的末尾添加数据,不支持在文件的任意位置进行修改。地理空间数据的处理,如单条地理对象 的查询,数据量不是很大,但要求查询延时短; 为了方便对空间数据的处理,地理位置相邻的空间对象尽可能在逻辑存储上也相邻,所以对地理数据执行添加操作时,不能简单地将记 录添加到文件末尾; 空间数据经常更新,而 HDFS 不支持文件在任意位置的修改。综上所述,仅使用 HDFS 存储空间数据并不合适。
HBase 适合于存储大数据,支持单条记录的快速查询,在任意指定位置单条或批量添加、删除数据。HBase 是基于列稀疏存储的行/列矩阵,不存储列值为空的表元素,大大节省了存储空间。HBase 与 HDFS 一样,支持 MapReduce 框架作分布式计算操作。HBase 的行键设计灵活,自动按照字典序排序。HBase 的这些特性,十分适合存储和处理空间数据[1]。
为了能够高效存储和处理空间数据,本文研究基于 HBase 的分布式存储,釆用网格法对地理空间进行划分,构建索引表,计算出每个网格单元对应的 ID,设计行键和列族方案,提高查询效率,为解决空间矢量数据存储与处理问题提供一种初步的探索方案。
1 相关工作
1.1 Hbase 数据模型
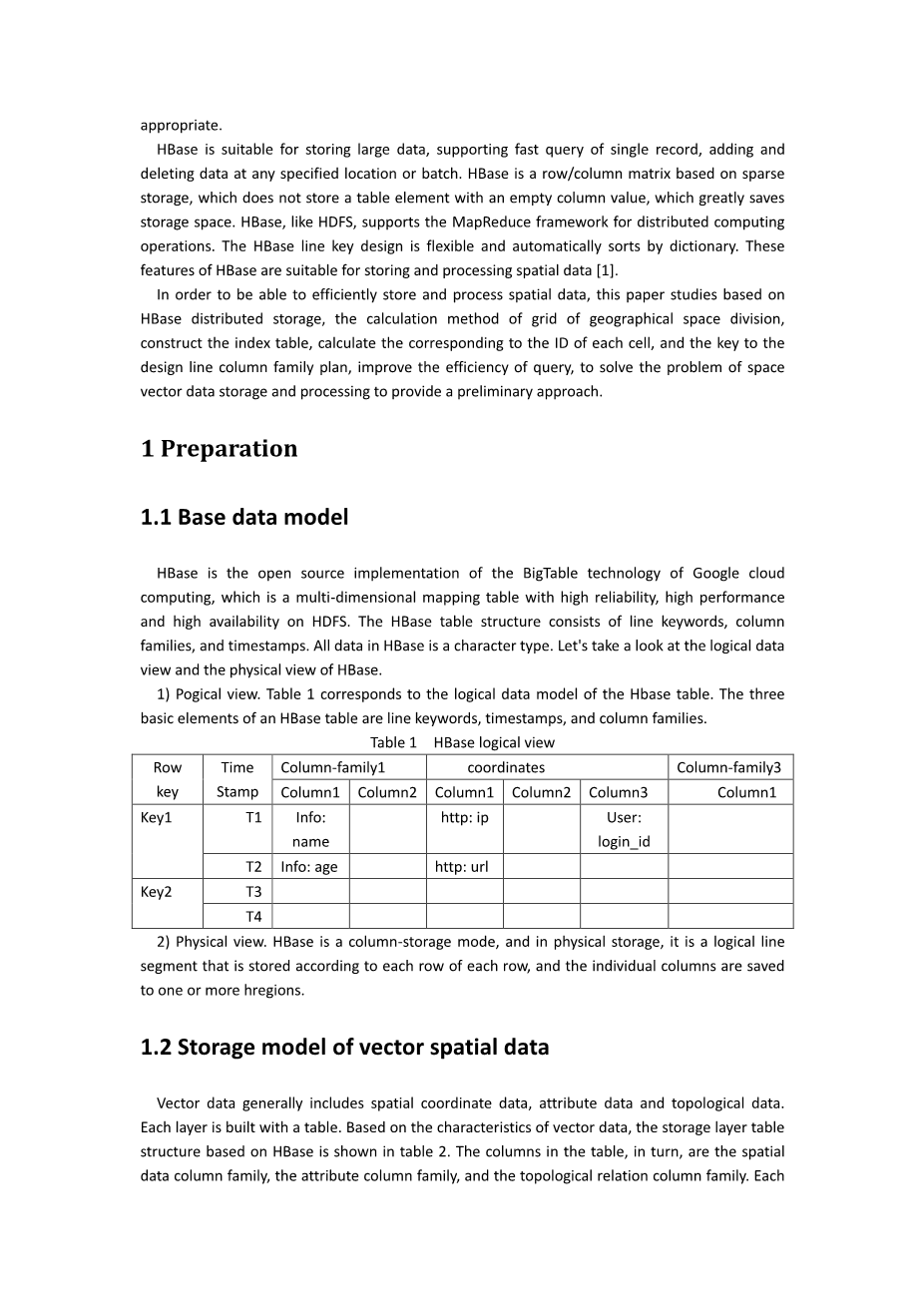
HBase 是 Google 云计算的 BigTable 技术的开源实现,它是一个架构在 HDFS 上的面向列的、多维度的映射表,具有高可靠性、高性能和高可用性。HBase 表结构由行关键字、列族、时间戳组成。HBase 中所有数据都是字符类型。下面介绍一下 HBase 的逻辑数据视图和物理视图。
1) 逻辑视图。表1对应了 Hbase 表的逻辑数据模型。一个 HBase 表组成的 3个基本元素为行关键字、时间戳和列族。
表1 HBase 逻辑视图
|
Row key |
Time Stamp |
Column-family1 |
coordinates |
Column-family3 |
|||
|
Column1 |
Column2 |
Column1 |
Column2 |
Column3 |
Column1 |
||
|
Key1 |
T1 |
Info: name |
http: ip |
User: login_id |
|||
|
T2 |
Info: age |
http: url |
|||||
|
Key2 |
T3 |
||||||
|
T4 |
|||||||
2) 物理视图。HBase 是列存储模式的,在物理存储方面,它是将逻辑上的行分割,并按照每行的各个列族来存储, 将各个列族保存到一个或多个 HRegion 中。
1.2 矢量空间数据的存储模型
矢量数据一般包括空间坐标数据、属性数据和拓扑数据。 每一个图层建一张表,根据矢量数据的特点设计的基于 HBase 的存储图层表结构如表2所示。表中的列族依次是空间数据列族、属性列族和拓扑关系列族。每种数据格式都是字符串类型,使用时解析成相应的数据类型[2]。
表2 矢量数据图层的表结构
|
Row key |
Time Stamp |
attribute |
coordinates |
stopo |
||
|
attr1 |
Attr2 |
Attr3 |
||||
|
ID1 |
t3 |
|||||
|
t2 |
||||||
|
t1 |
topo1 |
|||||
对于矢量数据,根据不同比例尺、不同图层建立不同的表,表之间没有关系,Row key 是图层中矢量要素的唯一ID号。属性数据可有多行,每行代表矢量要素的一种属性; 坐标数据采用熟知二进制 ( Well-Known Binary,WKB) 格式存储[3];如有拓扑关系数据,则将数据存储到拓扑列族中。
2 矢量空间数据的存储
2.1 矢量空间数据存储的改进总体思路
基于 HBase 的空间数据处理研究尚在起步阶段,相关文献比较有限。在先前的研究中,主要关注点是采用 Hilbert 曲线降维法将多维坐标降维为字符串[4 - 5],以便 HBase 存储和处理。Hilbert 曲线降维法的优点是Hilbert 能够利用数学模型将多维坐标降维为字符串,并且能够最大限度地保证空间对象之间的逻辑相关性; 缺点是降维过程中运算量比较大,尤其当空间数据总量发生变化的情况下,需要重新构建 Hilbert 排列码及索引顺序号,对后续的数据处理带来极大的不便。
不同于 Hilbert 曲线降维的方法,丁琛等[6]提出结合 HBase 的机制和 Shapefile 格式空间数据特点,设计 HBase 表的行键。同时提出利用 HBase 内部提供的过滤机制,将空间数据中多维坐标的操作转化为 HBase 中多个一维字节流的操作[7 - 8],行键设计为空间对象几何中心横坐标 纵坐标 图层,但是按这种方式存储数据,扫描时先按横坐标后按纵坐标,这种排序导致了很多南北位置簇之间的跳跃。空间里彼此接近的点在 HBase 里不一定彼此接近。每次从北方位置簇跳到南方位置簇就意味着读取了不需要的数据。
本文在文献[6]的基础上,加入数据划分的思想,提出了一种改进的适合空间数据处理的 HBase 行键的方法,为数据的分布式或并行操作提供基础,并行处理策略能大大提高 GIS 的能力。在行键方案基础上,具体设计集空间对象几何中心坐标点纵坐标和图层信息的组合列族,设计为过滤列族,使得 HBase 方便高效地管理矢量空间数据,大幅提高查询的处理速度。
2.2 矢量空间数据存储行键方案
本文采用网格法[7]对地理空间进行划分,计算出每个网格单元的 ID,作为行键的一部分。将表的行键设计为网格索引 ID 空间对象几何中心点横坐标 空间对象几何中心点纵坐标 空间对象图层。这样设计的原因如下:
1) 每一个空间对象都抽象为一个坐标点。点对象本身就是用点坐标表示,无需转换。线和面是由一系列的坐标串组成,可以把它们抽象为图形的几何中心坐标点。
2) 分别取出二维坐标点的横坐标和纵坐标,通过字符串的方式将横坐标和纵坐标进行拼接。为了提高空间查询的效率,需要对入库的不同图层数据构建空间索引。在网格空间索引中,根据不同的比例尺应划分不同尺度的网格。使用网格索引 ID 进行区分。同时不同图层的空间对象可能几何中心坐标相同,为了最大可能性地保证空间对象与行键的唯一对应性,行键中需要加上图层信息。假设有一个空间对象,网格索引 ID,它属于 L 图层,其几何中心坐标点为 P( x,y) 。它的行键可以设计成 ID x y L。
3) 根据行键长度设计的原则,结合空间数据的特性,将行键的长度定义为32字节( 8字节的整数倍) ,其中ID占6字节,x 坐标占12字节,y 坐标占11字节,图层占3字节。
例如某一个空间对象的ID为 005401,图层属性为river, 其几何图形中心坐标点为 ( 120.564 324 567 890 854, 61.897 657 1) ,则它的行健设计为: 00540112056432456761897657100riv。
这种行键设计的特点:
1) 行键与空间对象一一对应。使用 ID、横坐标、纵坐标和图层信息能最大可能地保证空间对象与行键的唯一对应。
2) 适合数据检索。行键在 HBase 中按字典序排序[8],首先是按照对象所在的网格 ID 字典序排列,当 ID 相同的情况下,按照几何中心坐标点横坐标字典序排列,当横坐标相同的情况下,按照对象的几何中心坐标点纵坐标字典序排列,当横坐标和纵坐标都相同的情况下,按照图层信息的字典序排列。行键的排序特点在一定程度上适合于空间数据的检索。
2.3 矢量空间数据存储列族设计
矢量空间对象一般至少包括两种数据属性: 几何属性和非几何属性。因此,存储空间数据的 HBase 表应包含2个基本列族: 几何属性列族和非几何属性列族[9 - 10]。为了进一步筛选查询纵坐标范围的行键,方便空间数据的处理,本文在前述文献基础上提出利用 HBase 的过滤机制,将空间对象几何中心坐标点的纵坐标信息和图层信息存储到 HBase 表中,并为其专门设计一个列族,称为过滤列族,用它来限定行键筛选的范围,运用捆绑过滤的方法加快空间数据的处理。
2.3.1 几何属性列族和非几何属性列族
将几何属性数据存储在 Geometry ( 几何属性) 列族中。 该列族包含POINT( 点) 、LINESTRING( 线) 和 POLYGON( 面) 3 个 列,分别表示为 ( Geometry: POINT ) 、( Geometry: LINESTRING) 和( Geometry: POLYGON) 。存储的列值中点对象为一个坐标点,GeoTools 存储形式为( x y) ; 线对象为首尾不相连的一列坐标串,GeoTools 存储形式为( x1 y1,x2 y2,hellip;, xn yn ) ; 面对象为首尾相连的一列坐标串,GeoTools 存储形式 为( ( x1 y1,x2 y2,hellip;,xn yn,x1 y1 ) ) 。Geometry 列族的设计如表 3 所示。
表3 Geometry列族设计
|
Row key |
Column Family: Geometry |
|
|
Qualifiler |
Value |
|
|
ID1 |
POINT |
( x y) |
|
ID2 |
LINESTRING 全文共9917字,剩余内容已隐藏,支付完成后下载完整资料 资料编号:[11917],资料为PDF文档或Word文档,PDF文档可免费转换为Word |
|

