
英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
基于监督学习的皮肤病变自动分割
摘要
自动皮肤病变检测的准确性在皮肤癌的计算机辅助诊断(CAD)中很重要。本文提出了一种自动皮肤病灶分割的新方法来获得准确的边界。首先由Otsu的阈值法进行病变区域提取。其次,利用亲和传播聚类方法(AP)获得初始病灶周围的外围区域,利用简单线性迭代聚类(SLIC)将外围划分为小均匀子区域。最后,通过监督学习将均匀子区域划分为背景皮肤和病灶,并获得准确边界。对所提出的方法和其他四种最先进的自动方法进行的一系列实验表明,所提出方法的分割结果具有更好的准确性和鲁棒性。
介绍
皮肤癌是世界上发病率最高的癌症之一,而源于皮肤的黑色素瘤是最常见的恶性肿瘤,其发病率比任何其他癌症都快[1,2]。如果早期发现皮肤癌并手术治疗,治愈率会更高[3]。目前,诊断的准确性取决于医生的经验,CAD对于皮肤病变具有十分重要的意义。皮肤镜是一种非侵入性的皮肤成像技术,使得表面下的结构更易于看见。然而,研究表明,皮肤镜检可能实际上降低了缺乏经验的皮肤科医生的诊断准确性。因此近十年来自动数字皮肤镜图像分析方法的发展引起了广泛的关注。
近年来,已经出现很多定位病灶分割方法,大多数自动分割方法可以主要分为3类:直方图阈值,聚类和区域合并。一般而言,这些方法可以为具有强烈对比度和均匀纹理的图像提供良好的准确性,但对于对比度弱,质地不均匀和颜色多样的图像,效果并不理想。当图像中存在颜色变化和照明时,直方图阈值[4]无法找到明确的阈值来将病变与周围的皮肤分开。而聚类算法[5]可能会出现伪像,平滑病变与皮肤之间的过渡区域,以及病灶内多碎片病变或杂色着色。统计区域合并(SRM)[6]很难处理以噪声,伪像,结构,颜色变化,多种病变和弱边界分离为特征的图像。
如上所述,大多数病变分割方法或多或少遭受具有挑战性的条件。对于这样的挑战,他们经常会得到不准确的边界,这些边界落入同质区域。然而,我们需要将边界作为两个不同地区的边界。不准确的边界是导致分割质量低下的主要因素。为了解决这些问题,我们把重点放在靠近病变边界的精细分割上,并提出了一种新颖的方法来处理具有挑战性的图像。图1为所提出的方法的概述。首先,输入图像被分成子区域,并且分别为每个病变和背景子区域提取特征。其次,基于监督学习生成分类模型。最后,对于一个子区域我们使用模型来预测是否为病变。
本文的其余部分安排如下。在第2节中,介绍了在病变边界附近获得均匀的子区域。第3节描述了特征提取。第4节介绍支持向量机。第5节描述了分割过程。第6节显示了实验结果和分析。最后,第7节给出了结论和未来的工作。
|
|
|
图1 系统结构图 |
在边界线附近获得均质的小分区
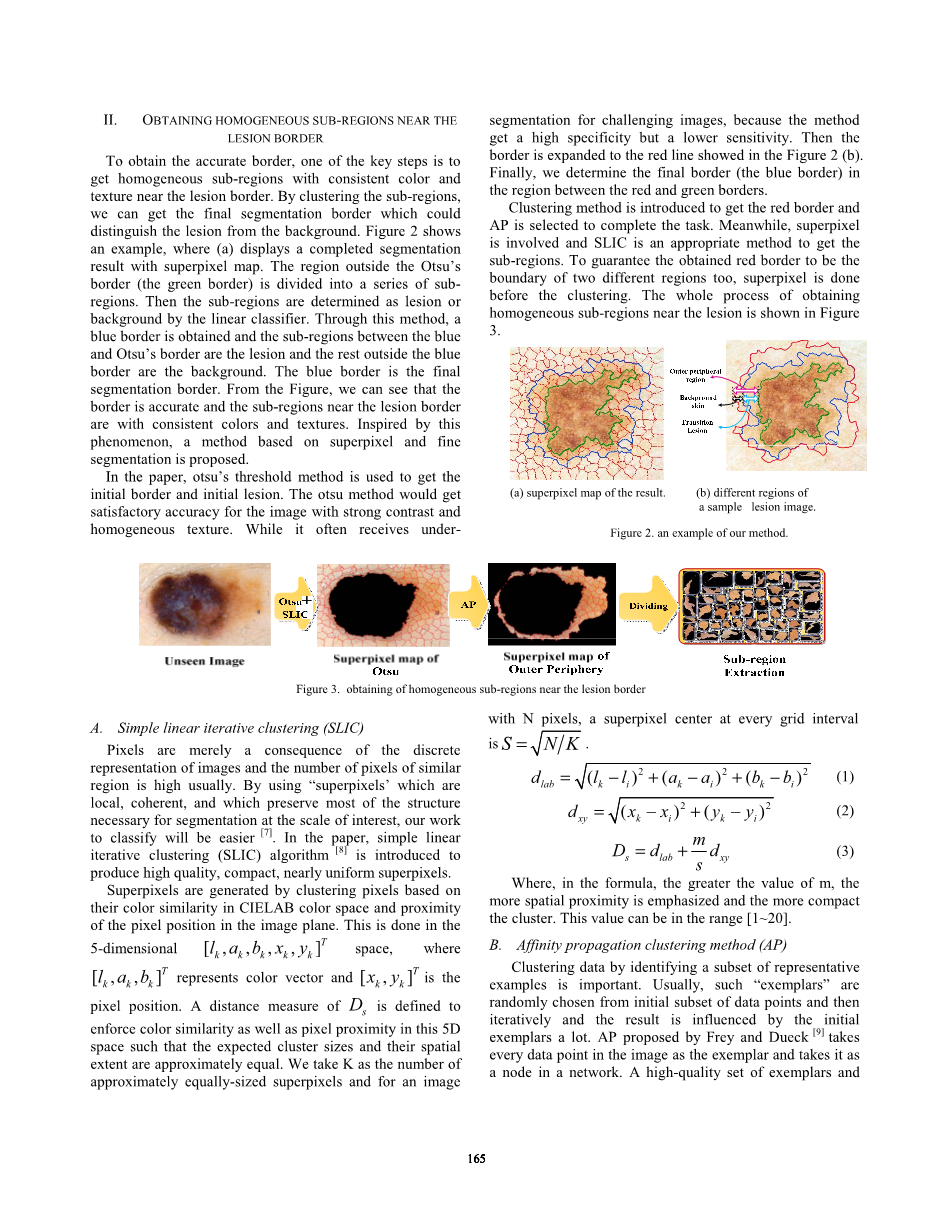
为了获得准确的边界,其中一个关键步骤是在病变边界附近获得具有一致颜色和纹理的均匀子区域。通过对子区域进行聚类,我们可以得到最终的分割边界,以区分病变区域和背景。图2显示了一个例子,其中(a)显示了具有超像素映射的完整分割结果。Otsu边界以外的地区(绿色边界)被划分为一系列的子区域。然后子区域将通过线性分类器确定为病变或背景区域。通过这种方法,获得蓝色边框,蓝色和Otsu边界之间的子区域为病变,蓝色边界外的其余部分为背景。蓝色边框是最终的分割边界。从图中,我们可以看到边界是准确的,靠近病变边界的子区域具有一致的颜色和纹理。受此现象的启发,提出了一种基于超像素和细分割的方法。
在本文中,otsu的阈值方法被用来获得初始边界和初始病变区域。 otsu方法对于具有强对比度和均匀纹理的图像将获得令人满意的准确性。 虽然它经常会遇到欠图像的挑战,因为该方法具有较高的特异性,但灵敏度较低。 然后将边界展开为图2(b)中显示的红线。 最后,我们确定红色和绿色边框之间区域的最终边框(蓝色边框)。
|
|
|
|
(a)超像素映射 |
(b)一副病变区域的不同采样区域 |
|
图2 本文方法的示例 |
|
引入聚类方法获取红色边框,选择AP完成任务。 同时,涉及超像素的地方,SLIC是获取子区域的合适方法。 为了保证获得的红色边界也是两个不同区域的边界,在聚类之前完成超像素的划分。 在病灶附近获得均匀的子区域的整个过程如图3所示。
|
|
|
图3 在病变边界附近获得均匀的子区域 |
简单的线性迭代聚类(SLIC)
像素仅仅是图像的离散表示的结果,并且类似区域的像素数量通常很高。通过使用“超像素”,这些超像素是局部的,连贯的,并且保留了大部分分割所需要的结构,而我们的分类工作将更容易[7]。在本文中,简单线性迭代聚类(SLIC)算法[8]被引入生产高质量,紧凑,几乎均匀的超像素。超像素通过基于CIELAB颜色空间中的颜色相似性和像平面中的像素位置的接近度对像素进行聚类而生成。这是在5维空间中完成的,其中代表颜色矢量,是像素位置。 Ds的距离度量被定义为强制颜色相似性以及在这个5D空间中的像素邻近度,使得期望的簇大小和它们的空间范围近似相等。我们取K作为近似相等尺寸的超像素的数量,对于N像素的图像,每个网格间隔的超像素中心为。
其中,在公式中,m的值越大,则空间邻近度越强,而簇越紧密。该值可以在[1~20]的范围内。
亲和传播聚类方法(AP)
通过识别代表性示例的子集对数据进行聚类很重要。 通常,这些“样本”是从数据点的初始子集中随机选择,然后迭代地进行,结果受到初始样本的影响很大。 由Frey和Dueck [9]提出的AP将图像中的每个数据点作为示例,并将其作为网络中的一个节点。通过在数据点之间传递消息,样本病灶图像的不同区域相应的群集逐渐出现。
在递归消息传递期间,消息被更新以搜索适当选择的能量函数的最小值。 这个范例是他与他的集群相似度最高的范例。 数据xi和xk的相似度被定义为:
基于样本和数据样本之间的相似度构建相似度矩阵,并且当一个数据点选择另一个数据点作为样本时,分别更新两种类型的消息(可靠性和可用性)。
可靠性反映了xk被选为xi样本的可信度。更新规则如下:
从候选示例点k发送到点i的可用性反映了关于点i选择点k作为其示例的适当性的累积证据,考虑到其他点的支持,即k点应该是一个示例。更新规则如下:
通过计算最大化 ,k被确定为i的范例。
特征提取与融合
在分类阶段,引入了包括Gabor和灰度共生概率(GLCP)纹理特征和颜色特征的融合特征,这可以实现更高的精度。 在文献[10]中注意到,“维度诅咒”已被证明不会影响使用所提出的78-D融合特征的分类。
纹理特征
Gabor纹理特征:本文采用Gabor滤波器提取Gabor滤波器的频率和方向表征,其纹理特征与人类视觉系统相似,有助于特别合适的纹理表示和辨别。 2D Gabor函数是空间域中的高斯调制的复正弦波,并且Gabor滤波器配置允许完全覆盖空间频率平面。
复指数有一个空间频率和一个方向,影响纹理特征和最终的区分。完整的Gabor滤波器字典设计方案和特征提取过程已在[11]中充分描述。在[12]中,作者为自然图像设置UH = 0.4, UL = 0.05,方向= 6,尺度= 4。 UH和UL表示感兴趣的低频和高频中心频率。通过实验,我们发现相同的参数是适当的。
每个像素都会对每个滤镜有一个响应,所以每个像素都由一个48维的特征向量表示。假定局部纹理区域在空间上是均匀的,并且使用变换系数的大小的平均值和标准偏差来表示用于分类的区域。
最后,我们得到一个图像的48维(6 * 4 * 2)特征向量:
灰度共生矩阵:灰度共生矩阵(GLCM)[13]通常用于纹理统计分析。 当像素间距离设置为1或2,并且掩模尺寸设置为5times;5时,相应的GLCP特征非常好地测量局部高频信息。在本文中,GLCP功能用于替代高频Gabor滤波器功能。 对于存在点噪声的较高频率,Gabor滤波器会产生不一致的测量结果[12]。从GLCM计算三种纹理特征[14],包括对比度,相关性,熵,以量化皮肤镜图像的纹理。在本文中,方向设置为4(0,45,90,135),则GLCM特征的24维(3 * 2 * 4)向量被表示为:
颜色特征
颜色是图像最直观,最明显的特征,分别计算RGB颜色空间每个通道上的块的平均值。颜色是变化的,不同种类的病变具有不同的颜色,并且需要每一片的颜色比例来提高颜色值特征的效果。 所以我们也定义一个新的比率为:
其中,是第j个图像的第i个通道的平均值,是第j个图像的平均值。 所以我们得到一个颜色特征的6维(3 * 2)向量:
监督学习
支持向量机(Support Vector Machine,SVM)[15]最近因其坚实的理论基础和卓越的分类实际性能而被广泛使用。支持向量机的基础是结构风险最小化(SRM)原理,它可以减少过拟合和基于内核的学习算法,将数据映射到高维空间以提高线性学习的性能。
与其他三个基本核核函数:线性,多项式和sigmoid相比,径向基函数核(RBF)是优选的[14]和LIBSVM [16]集成软件(版本3.14)用于监督学习和分类。为了找到能够获得未来未见图像最大预测精度的最优模型,将适当的内核参数C(代价/惩罚)和(内核宽度),并根据十则交叉法的分类准确性采用网格搜索方法[14]。首先,通过在更大范围的Cisin;{2-1,2-3,...,2-15}和isin;{2-10,2-13,...,23}之间搜索来确定初始参数,然后搜索是在C周围的较小范围内再次完成的选择刚才选择最好的。
通常,良好融合的74维特征集通常具有不同的范围,这将导致内核计算中的数值不稳定性。为了避免这种情况,归一化是由[11]给出的z-score变换[17]中最常见的归一化方法完成的。
拍照完毕通知算法进行分析
其中,表示第i个样本的第j个特征的值; 和分别是第j个特征的均值和标准差。
分割
在本节中,分割方法分为两个阶段:训练阶段和分割阶段。在训练阶段,请有经验的皮肤科医师描绘病灶的准确轮廓。图像分为两部分:手工边界外的背景部分和手册与Otsu边界之间的病灶部分。首先对两部分进行标记,并用第二部分的方法提取一系列同质的子区域。其次,从每个子区域提取第3节介绍的标记融合特征以表示病变和背景皮肤。在训练阶段的最后阶段,通过LIBSVM中的监督学习生成分类器模型。
在分割阶段,不可见的图像被分割成子区域,如图3所示。然后为每个子区域提取78-D融合特征。接下来,用所生成的分类器模型预测子区域。最后,通过合并预测的病灶和初始病灶自动划分最终结果。图4显示了特征提取,子区域分类,病灶合并和描绘的过程。我们可以看到图3和图4的组合显示了一个测试图像分割的整个过程。
|
|
|
图4 部分分割流程 |
125组恶性黑色素瘤皮肤镜图像的实验数据集在网站下载(https://dermoscopy.k.hosei.ac.jp/DermoPerl/)。特征数据集使用从125恶性黑素瘤皮肤镜图像中提取的78-D矢量融合特征集。
图5是一组分割实例,包括使用包括直方图阈值[18],方向敏感模糊C均值(FCM)[5],统计区域合并(SRM)[6]和在[19]中提出的方法。文献[19]中的方法涉及使用Mean shift将训练图像聚类为均匀区域; 然后基于每个聚类区域提取融合纹理特征。
然后基于Gabor和GLCM特征从每个聚类区域中提取融合纹理特征; 接下来,通过LIBSVM的监督学习生成分类器模型。 最后,通过生成的分类器预测未见图像的病变区域。
在图5中,蓝线是手动标记的边界,红线是自动确定的边界。 可以看出,当病灶物体颜色不均匀,病灶及其周围皮肤和气泡之间的对比度较弱时,我们的方法得到的分割结果与人工边界更加一致。 在图5中,SRM的第四个分割(由蓝线表示)由于对比度弱而失败。
|
|
|
图5 在不同方法下的分割结果 |
lt;
全文共9685字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[15489],资料为PDF文档或Word文档,PDF文档可免费转换为Word

