
英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
边缘智能:借助“设备-边缘协同”
实现深度学习模型推理
摘要
作为直接推动机器学习蓬勃发展的关键核心技术,深度学习已经迅速成为学术界与工业界关注的焦点。然而,由于深度学习模型的高精度需求往往会引发对计算资源的大量消耗,因此将一个深度学习模型部署到资源受限的移动设备面临着的巨大的挑战。本文介绍Edgent,一个基于边端协同的按需加速深度学习模型推理的优化框架,通过深度学习模型分割与模型精简实现加速。实验表明其能在网络边缘端高效支撑深度学习应用。
关键字 边缘智能,边缘计算,深度学习,计算卸载
1 引言与相关工作
作为支撑现代智能应用的关键核心技术,深度学习代表了当下最火热的机器学习技术,深受学术界与产业界的高度重视。由于深度学习模型的高准确率与高可靠性,深度学习技术已在计算机视觉[14]、语音识别[12]与自然语言处理[16]领域取得了广泛的成功应用,相关产品正如雨后春笋般涌现。然后,由于深度学习模型推理需要消耗大量的计算资源,当前的大多数移动设备由于资源受限而无法以低延迟、低功耗、高精确率的方式支持深度学习应用。
为了应对深度学习模型对计算资源的巨大需求,当下通行的方式是将深度学习模型的训练与推理都部署在云端数据中心。在执行深度学习模型推理的时候,移动端设备将输入数据发送至云端数据中心,云端推理完成后将结果发回移动设备。然而,在这种基于云数据中心的推理方式下,大量的数据(如,图像和视频数据)通过高延迟、带宽波动的广域网传输到远端云数据中心,这造成了较大的端到端延迟以及移动设备较高的能量消耗。相比于面临性能与能耗瓶颈的基于云数据中心的深度学习模型部署方法,更好的方式则是结合新兴的边缘计算技术,充分运用从云端下沉到网络边缘(如基站、Wi-Fi接入点等) 端的计算能力,从而在具有适当计算能力的边缘计算设备上实现低时延与低能耗的深度学习模型推理。
在取得基于边缘的深度神经网络(DNN)推理的优势前提下,我们的经验学习结果表明基于边缘的DNN推理高度敏感于边缘服务器和移动设备之间的传输带宽。特别地,当带宽从1Mbps降到50Kbps时,延迟从0.123s增长至2.317s,与DNN本地推理无异。因此,考虑到实际场景中的网络带宽在用户移动性和竞争下就是不稳定的,一个很重要的问题运行而生:我们如何才能进一步提高基于边缘的DNN推理的性能(延迟角度),尤其是一些像VR/AR、机器人学[13]等任务敏感型的任务。
为此,本文介绍我们所提出的Edgent,一个基于边端协同的按需加速深度学习模型推理的优化框架。为了满足新兴智能应用对低时延和高精度日益迫切的需求,Edgent采取以下两方面的优化策略:一是深度学习模型分割,基于边缘服务器与移动端设备间的可用带宽,自适应地划分移动设备与边缘服务器的深度学习模型计算量,以便在较小的传输延迟代价下将较多的计算卸载到边缘服务器,从而同时降低数据传输时延和模型计算延迟;二是深度学习模型精简,通过在适当的深度神经网络的中间层提前退出,以便进步减小模型推理的计算时延。然而值得注意的是,虽然模型精简能够直接降低模型推断的计算量,但模型精简同样会降低模型推断的精确率(提前退岀神经网络模型减少了输入对数据的处理,因而降低了精确率)。针对模型精简所引发的延迟与精确率之间的折衷关系,Edgent以按需的方式协同优化模型分割与模型精简,即对于一个具有明确时延需求的一个模型推理任务,Edgent在不违反其时延需求的前提下选择最佳的模型分割和模型精简策略来最大化其模型推理的准确率。本模型的实现于进一步的评估基于树莓派开发板。
本文的研究与现有边缘智能方面的相关工作不同且互为补充,一方面,对于移动端设备的低时延与低功耗的深度学习模型推理,已有许多面向移动终端高效执行的深度学习模型压缩与深度学习架构优化的方法被提出[3-5, 7, 9],不同于这些工作,本文采取一种“向外扩展”( Scale out)的方法来克服终端所面临的性能与能耗瓶颈。具体而言,本文通过模型分割这种优化策略来灵活融合边缘服务器的强计算力与终端设备计算本地性的异构优势,从而最大程度发挥边端融合在降低模型推理延迟方面的作用。另一方面,虽然此前已有相关文献提出模型分割方法来加速深度学习模型推理过程[6],本文进一步提出模型精简这一优化策略,并将其与模型分割相结合进行协同优化,从而进一步加速深度学习模型推理过程。
2 研究背景与动机
本章节首先给出DNN的预备知识,随后分析基于边缘和基于设备的DNN执行的低效,最后展示DNN分割和模型精简的优势。
2.1 DNN预备知识
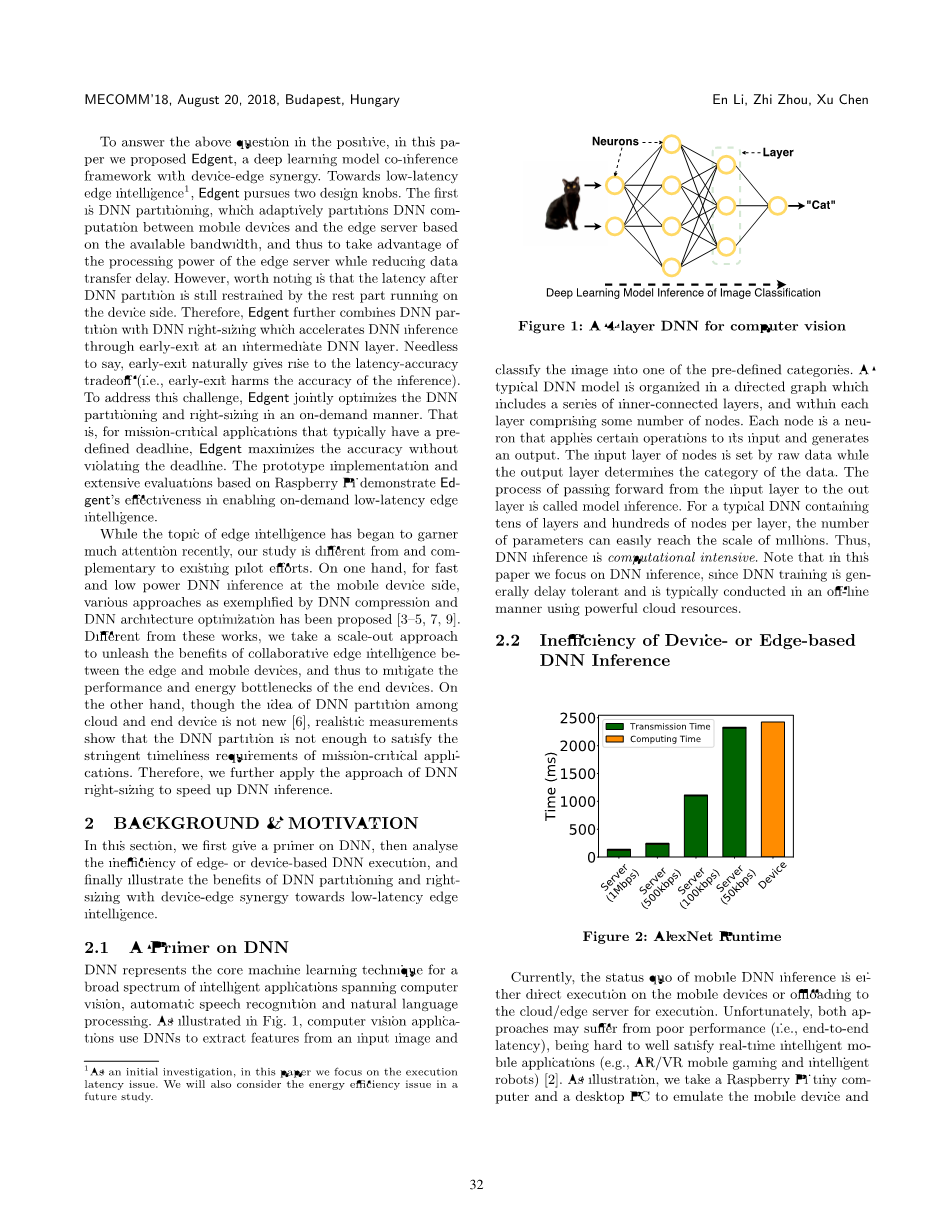
DNN代表了机器学习的核心技术,被广泛应用于计算机视觉,自动化语音识别和自然语言处理。如图1所示,计算机视觉应用借助DNN分析输入图像的特征,然后将该图像分类到预先定义的类别中。一个典型的DNN模型是一个有向图,包含一系列相互连接的层,每一层由一系列节点组成。每一个节点是一个执行特定操作且生成输出的神经元。输入层由原始数据设定,输出层则决定了原始数据的类别。模型推理就是从输入层到输出层地数据传递。一个典型的DNN通常包括数十层,每一层由上百个节点,因此参数个数很容易突破百万级别。因此,DNN推理时计算密集型任务。本文只考虑DNN推理,因为DNN训练可以在延迟容忍度高的条件下,通过云的强大算力线下训练完成。
图1 适用于计算机视觉的4层DNN
2.2 基于设备和基于边缘的DNN推理的劣势
图2 AlexNet运行时
当前,针对运行在移动端设备的智能应用,实现深度神经网络模型推理的方法要么是在移动端设备上直接执行,要么将其加载至云数据中心或边缘服务器执行。但这两种方式都可能存在较差的性能(即端到端时延),难以很好地满足实时移动智能应用,如AR/VR、移动游戏和智能机器人[21]。图2展示了经典卷积神经网络AlexNet在不同带宽环境下基于边缘服务器方式执行的性能表现。不难发现,其性能取决于输入数据从移动设备传输到边缘服务器所花费的数据传输时间(取决于带宽),因此,基于服务器方式的深度学习模型推理方法的端到端延迟对可用带宽高度敏感。考虑到带宽资源在实际环境中的稀缺性(用户之间或应用之间的带宽竞争)以及移动设备计算资源的限制,直接在设备端运行和在边缘服务器运行的方式都很难以实时地支持许多新兴的具有严格时延要求的移动智能应用。
2.3 DNN分割于模型精简
DNN分割:为了更好地理解DNN执行性能的瓶颈,我们将AlexNet每一层的运行时间和输出数据的大小列了出来,如图3所示。可以发现,具有更长运行时间的层不一定输出数据就很大。因此,一个很自然的动机就是将DNN切分成两部分,将计算密集的那一部分卸载到卸载到服务器上执行,以此减少端对端的时延。
图3 AlexNet在树莓派上的运行时
DNN模型精简:尽管DNN切分能够借助边缘服务器的计算能力显著地减少延迟,但是我们需要注意到最优的DNN切分仍然被设备端的运行时所限制。为了进一步减少延迟,我们提出了模型精简的策略。通过训练具有多个退出点的、模型大小各不相同的DNN,我们可以选择在保证精度要求的前提下具有最小计算延迟的模型,图4展示了一个具有多分枝的AlexNet。
图4 具有多个退出点的DNN模型精简示例
问题描述:显然地,DNN模型精简需要在延迟和精度之间做出权衡——尽管早退出可以减少计算时间,但这也会影响到DNN推理的精度。考虑到一些应用(例如VR/AR游戏)有明确的延迟要求,同时又可以忍受一定程度上的精度上的损失,在这类应用上我们就可以去的延迟和精度上的合理权衡。
3 Edgent优化框架
3.1 系统概览
针对深度学习模型应用部署的挑战,权衡模型推断与精度之间的折衷关系,我们定义如下研究问题:对于给定时延需求的深度学习任务,如何联合优化模型分割和模型精简这两个决策,从而使得在不违反时延需求的同时最大化深度学习模型的精确度。针对上述问题,我们提出了基于边缘与终端协同的深度学习模型运行时优化框架Edgent[15]。如图5所示,Edgent的优化逻辑分为三个阶段:离线训练阶段,在线优化阶段以及协同推断阶段。
上述基于边缘服务器与终端设备协同的深度学习模型推断框架思路为:在离线阶段,我们训练好任务需求的分支网络,同时为分支网络中的不同神经网络层训练回归模型,以此估算神经网络层在边缘服务器与终端设备上的运行时延;在在线优化阶段,回归模型将被用于寻找符合任务时延需求的退出点以及模型切分点;在协同推断阶段,边缘服务器和终端设备将按照得出的方案运行深度学习模型。
离线训练阶段。Edgent需要执行两个初始化操作:(1)分析边缘服务器与终端设备性能,针对不同类型的深度学习模型网络层,如卷积层,池化层等,生成基于回归模型的时延估算模型。在估算网络层的运行时延时,Edgent会对每层网络层进行建模而不是对整个深度学习模型进行建模,不同网络层的时延是由各自的自变量(如输入数据的大小、输出数据的大小)决定,基于每层的自变量,我们可以建立回归模型估算每层网络层的时延;(2) 训练带有多个退出点的分支网络模型,从而实现模型精简,这里我们采用BranchyNet分支网络结构,在BranchyNet结构下,我们可以设计并训练出带有多个退出点的分支网络。图4展示了具有5个退出点的AlexNet模型,目前多退出点的深度神经网络模型由开源框架BranchyNet[14]支持。需要注意的是,性能分析取决于设备,而深度学习模型是取决于应用的,因此在给定设备的情况下即限定边缘服务器与终端设备,以上两个初始化操作在离线阶段只需要完成一次。
图5 Edgent概览
在线优化阶段。在这个阶段,主要工作是利用离线训练的回归模型在分支网络中找出符合时延需求的退出点以及模型分割点,因我们需要最大化给出方案的准确率,因此在线优化阶段中是通过迭代的方式,从最高准确率的分支开始,迭代寻找出符合需求的退出点和切分点。在这个过程中,Edgent实时测量当前移动终端与边缘服务器之间链路的网络带宽,以便于估算移动终端与边缘服务器间的数据传输时延。紧接着,Edgent沿着尺寸从大到小的网络分支(如图4中从右至左的5个网络分支),依次遍历每个网络分支上不同的分割点,并基于当前网络带宽和不同网络层计算时间估算所选网络分支与分割点对应的端到端延迟与模型精确度。在遍历完所有的分支网络与切分点后,Edgent输出满足时延需求的所有网络分支与切分点组合中具有最大精确度的一个组合。
协同推断阶段,根据上述在线优化阶段所输出的最优网络分支与切分点组合,边缘服务与移动终端对深度学习模型进行协同推断。
3.2 模型延迟预测
表1 回归模型的自变量
Edgent对每一层的延迟建模,而非整个DNN。通过实验,我们观察到不同层的延迟由各种自变量(例如,输入数据大小,输出数据大小)决定,如表1所示。注意,我们还观察到DNN模型加载时间也有明显的对整个运行时的影响。因此,我们进一步将DNN模型大小作为输入参数来预测模型加载时间。基于每层的上述输入,我们建立回归模型以基于其概况预测每个层的延迟。表2中显示了一些典型层的最终回归模型(大小以字节为单位,延迟以ms为单位)。
表2 每一层的回归模型
3.3 DNN切分与模型精简的同时优化
在线优化阶段,DNN优化器接收到来自移动设备的延迟要求,然后搜索对于训练的最佳出口点和分区点branchynet模型。 整个过程在算法1中给出。对于具有?出口点的分支模型,我们表示?-?h出口点有??层。 这里有一个更大的指数?对应更准确的更大尺寸的推理模型。 我们用上述回归模型预测???的?-?h层在设备和???上运行时的运行时间?-?h层在服务器上运行时的运行时。 ??是?-?h层的输出。在特定带宽?下,输入数据?????,然后我们计算??,?整体。当?=1,?=?时,运行时间(Sigma;︀?-1??? Sigma;︀??︀?? ?????/? ??-1 /?)?-?h是所选模型?-?h出口点的分区点。当?= 1时,模型只能在设备上运行,然后???= 0,??-1 /?= 0,?????/?= 0 当?=??时,模型只能在服务器上运行,然后???= 0,??-1 /?= 0.这样,我们就可以找到?-?h模型具有最小延迟的最佳分区点和出口点。由于模型分区不影响推理精度,我们可以依次尝试具有不同出口点(即具有不同精度)的DNN推理模型,并找到具有最大尺寸并同时满足延迟要求的模型。 请注意,由于预先训练了层延迟预测的回归模型,因此算法1主要涉及线性搜索操作,并且可以非常快速地完成(在我们的实验中不超过1ms)。
4 性能评估
本文基于Tesla P100 GPU服务器对多分支深度学习模型进行训练,以台式电脑作为边缘服务器,以树莓派作为移动端设备,对框架有效性进行验证。实验设计包含:设定任务时延需求,通过限定边缘服务与
全文共8087字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[2608]

