
英语原文共 14 页,剩余内容已隐藏,支付完成后下载完整资料
文献翻译
形状上下文下的动态时间弯曲
摘要
在时间序列数据挖掘中相似性度量方法至关重要。由于动态时间弯曲可以很好地处理时间扭曲,因此是一种应用广泛的方法。但是DTW也有它固有的缺点,它容易出现一条时间序列上的一个点对应另一条时间序列的大部分点的情况,造成病理性对应排列。为了克服这个缺点,我们提出了一种名为SC-DTW的新型DTW变体。SC-DTW采用形状上下文(一种丰富的局部形状描述)来替代常规的DTW对应的原始观测值。SC-DTW的主要创新点在于
(1) 它深入探讨了时间序列的数字性和形态性
(2) 它考虑了每个点的邻域信息
SC-DTW可以在时间序列之间生成一个特征到特征的对应,也因此是一个更加稳健的相似性度量方法。我们使用最近邻1-NN分类器在UCR时间序列数据集上对SC-DTW进行了测试。与其他已经成熟的方法相比,SC-DTW在34个数据集的24个中表现出了更好的精度。
- 前言
时间序列普遍存在于各个领域[16,31,18,32,29,7]。与静态数据相比,时间序列可以完全捕获一种现象的时间演变。时间序列分析的基本任务是定量测量时间序列之间的相似性[13,44,54]。目前,主流相似性度量如欧几里德距离和DTW[36]都是基于时间序列之间的对应提出的。基于对齐的相似性度量的准确性很大程度上依赖于对齐的质量。有两种对齐方式:时间刚性对齐和时间灵活对齐。
欧氏距离采用时间刚性对齐,两个时间序列的时间轴必须严格对齐;因此,它对时间扭曲很敏感。相比之下,DTW[36]允许时间灵活对齐;因此,它很好地处理时间扭曲的情况。由于时间扭曲在时间序列数据集中非常常见,因此DTW的使用越来越广泛。很多应用已经显示出它的优越性[32,4,35,17]。
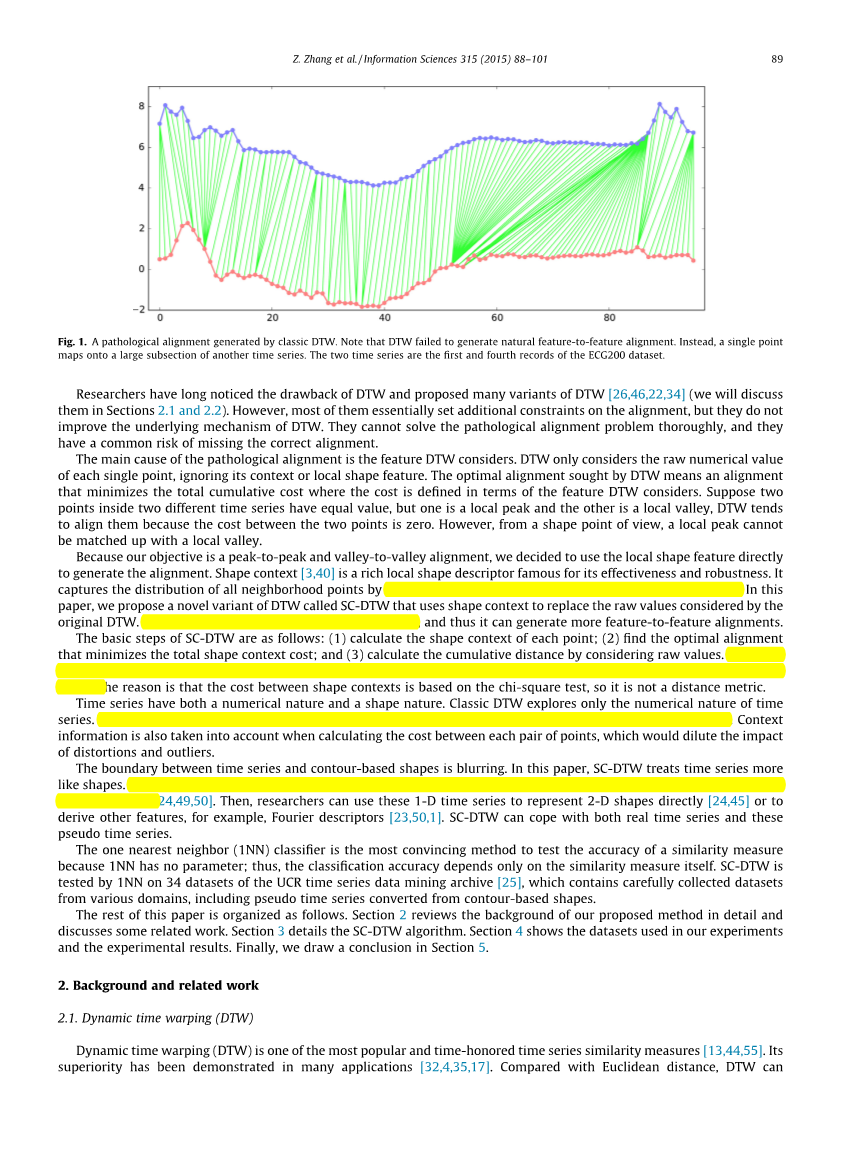
但是,DTW有其固有的弱点。在时间序列中,x轴表示观察时间,y轴代表观察值。DTW假设观测值的所有变化都是由时间失真引起的,即使没有时间扭曲存在[26]。因此,DTW倾向于通过扭曲x轴来解释y轴上的所有波动,导致病理结果。图1是由DTW产生的病理学比对的实例,图中单个点映射到另一个时间序列的大片点。理想的对齐方式应该是特征到特征,例如,局部峰值应始终与另一个时间序列中的相应峰值对齐,而不是与谷值对齐。
图 1 经典DTW产生的病理性对应
研究人员早就注意到了DTW的缺点,并提出了DTW的许多变种[26,46,22,34](我们将讨论在第2.1和2.2节中讨论它们。它们中的大多数基本上都在对应上设置了额外的约束,但没有改善DTW的潜在机制,无法彻底解决病理对齐问题有错过正确的对方应式的风险。
病理对齐的主要原因是DTW考虑的特征。DTW仅考虑每个单点的原始数值,忽略了其上下文或局部形状特征。 DTW寻求的最佳对应意味着最小化累计成本总额,其中成本是根据DTW考虑的特征来定义的。假设在两个不同时间序列内的两个点具有相等的值,但一个是局部峰值,另一个是局部谷值,DTW趋于对齐它们因为两点之间的成本为零。但是,从形状的角度来看,局部波峰不能与局部波谷相匹配。
因为我们的目标是峰-峰和谷-谷对齐,所以我们决定直接使用局部形状特征生成对齐。形状上下文[3,40]是一个富有的局部形状描述符,以其有效性和稳健性而闻名。它通过计算每个对数极点箱中的点数来捕获所有邻域点的分布。在这论文中,我们提出了一种名为SC-DTW的新型DTW变体,它使用形状上下文来代替原DTW。形状上下文比较局部邻域形状,因此它可以生成更多的特征到特征的对齐。
SC-DTW的基本步骤如下:
(1)计算每个点的形状上下文;
(2)找到最佳对齐方式,最大限度地减少总形状背景成本;
(3)通过考虑原始值计算累积距离。
注意我们只使用形状上下文来生成对齐,然后我们仍然采用原始值来计算累积距离。原因是形状上下文之间的成本基于卡方检验,因此它不是距离度量。
时间序列具有数字性质和形状性质。经典DTW仅探索时间的数字性质。我们提出的方法的新颖之处在于我们将时间序列视为1-D阵列和2-D形状。在计算每对点之间的成本时也会考虑上下文信息,这会减少扭曲和异常值的影响。
时间序列和基于轮廓的形状之间的边界模糊。在本文中,SC-DTW将时间序列视为形状。 然而,与我们的想法相反,形状也可以使用质心距离方法[24,49,50]转换为伪时间序列。 然后,研究人员可以使用这些1-D时间序列直接表示2-D形状[24,45]或导出其他特征,例如傅里叶描述符[23,50,1]。SC-DTW可以处理实时系列和这些伪时间序列。
最近邻(1NN)分类器是测试相似性度量准确性的最有说服力的方法,因为1NN没有参数。因此,分类精度仅取决于相似性度量本身。通过1NN在UCR时间序列数据挖掘档案[34]的34个数据集上测试SC-DTW,其中包含来自不同领域的精心收集的数据集,包括从基于轮廓的形状转换的伪时间序列。
本文的其余部分安排如下。第2节详细回顾了我们提出的方法的背景,并讨论了一些相关的工作。第3节详细介绍了SC-DTW算法。第4节展示了我们实验中使用的数据集和实验结果。最后,我们在第5节得出结论。
2.背景和相关研究
2.1 动态时间弯曲
动态时间弯曲时在时间序列度量上最流行的方法之一,它被应用于许多领域,相比于欧式距离,DTW通过在两个给定时间序列之间找到时间灵活的对齐来克服时间失真问题,其中总累积距离最小化。第一时间序列的每个点与第二时间序列的至少一个点对齐。图2(b)显示了DTW产生的时间灵活对齐。术语“基准距离”是指位于不同时间序列上的一对点之间的成本。
原始DTW使用的基本距离(我们称之为原始基本距离)定义为:
请注意,基本距离是平方的,以节省平方根运算的时间。
给定两条时间序列和以任意两点间的距离确定距离矩阵,如图2(c).所示
其中,
图 2 两种类型的对应和时间序列之间的弯曲距离
为了计算S和Q的动态时间弯曲距离DTW(S,Q),需要找到一条最优的弯曲路径,其中,使得S和Q的累积距离值达到最小,表示和的匹配关系,有。一般存在着多条弯曲路径,有效的弯曲路径P必须符合给出的三个要求:
边界性:
单调性:给定和,有
连续性:给定和,有
在众多有效的路径中找到唯一的最优路径使得累积距离达到最小,即
为求解上式,利用动态规划的方法构造一个代价矩阵,其中每个元素通过下式得到:
(1)
其中,,
故DTW=,得到最小累积代价后,为了得到最优弯曲路径,再反向以为起点寻找弯曲路径,直到时,寻找过程结束,最终得到完整的弯曲路径和两条时间序列的最佳对应(alignment)。
2.2 DTW的变体
DTW的缺陷在于它可能导致病理性排列,这一点早已被人们注意到[36]。 奇点是病理对齐的典型特征,其中单个点与另一个时间序列的大部分对齐。 已经提出了DTW的许多变体来减轻奇点问题。
1.窗口化是一种直观的解决方案,它限制了每个单点可以对齐的范围。 换句话说,允许的弯曲路径必须落入弯曲窗口。 窗口被广泛使用,并且已经提出了具有不同结构的各种弯曲窗[4,33,39,31]。图3示出了三种类型的变形窗口。在早期阶段,必须修复变形窗的结构。近年来,已经提出了学习某些数据集的自适应窗口的方法[34,46,6]。窗口化的动机是限制奇点的大小。因此,它不能产生奇点。
图 3 三种类型的时间约束窗
2.坡度加权,[36,22]用方程式(2)代替了方程式(1):
(2)
其中引入斜率权重参数Sr和S1以控制弯曲路径偏向对角线。
3.步数模式[21,31],用方程式(3)代替(1)
(3)
其中引入新参数a,b,c和d以定制每个步骤的方向和长度。 在实践中,一个a,b,c和d通常设置为非常小的整数,例如,0,1或2。
三类变体基本上都对弯曲路径设置了额外的约束。它们只能缓解奇点问题。他们中的另一个常见问题是他们有错过正确对齐的风险。而且,很难确定这些约束的有效参数。窗口是最受欢迎的方法,因为它相对有效且简单明了。DTW及其变体的全面实现可以在[14]中找到。
DTW的另一个变体是导数动态时间扭曲(DDTW)[26]。它没有将约束设置为变形路径,而是取代DTW考虑的特征。顾名思义,DDTW使用每个点的一阶导数作为新特征来找到最佳对齐。DDTW定义如下:
(4)
注意第一个点和最后一个点,他们的导数不能确定。
DDTW与我们提出的方法密切相关,因为它们都使用新特征来对齐时间序列。因此,我们选择DDTW作为实验中的对比方法之一,以及其他完善的相似性度量。
2.3形状上下文
形状上下文是一个丰富的形状描述符,由Serge Belongie和Jitendra Malik [2,3]提出,并成功地用于对象匹配。它以在小的几何变形和异常值下的稳健性而闻名。以形状轮廓上的参考点为中心,其形状上下文捕获其周围所有其他点的空间分布。图4示出了形状上下文的结构及其计算过程。形状上下文由统一的对数极坐标直方图定量表示。以某一个形状上的点P为圆心,作一个如下图(a)的圆盘,计算圆盘中每一个小格子内点的数量,用一个类似图(c)的直方图来表示,横轴表示12个扇面,纵轴表示中心最小的圆和从小到大的4个圆环,(c)中方格的深浅表示(a)中每一个小格子所包含的点数。称(c)为log-polar直方图。我们计算位于每个箱中的点数以获得总体直方图。
让hs和hq分别表示s点和q点的log-solar直方图,其中s、q分别是第一个形状上的点和第二个形状上的点,则形状上下文距离(shape context cost)定义为。
(5)
两个形状上的相应点之间的成本将很小。
图 4 形状上下文示意图
通常,形状上下文可以通过四个参数来描述:h,log(r),外半径(Router)和内半径(Rinner)。 外半径是最外圈的半径,内半径是最内圈的半径.默认值为:h为12,log(r)为5,外半径比内半径大16倍。Router很重要,因为它决定了形状上下文的大小,从而确定了相关点的数量。
形状上下文长期以来用于复杂的二维形状之间的距离测量。例如,半监督多视图距离度量学习(SSM-DML)[48]提取三个视觉特征,即形状上下文,颜色直方图和骨架特征,它们彼此互补,以描述卡通人物。形状上下文是表征形状的最相关的视觉特征。通过构建二维动画之间的对应来捕捉相似性的另一项工作[47]也采用形状上下文作为其形状描述符,因为形状上下文描述了特征点周围的地标点的相对空间分布,并且它对旋转是不变的。 然后,提出了半PAF(斑块对齐框架)[47,52]用于对应构造。
使用形状上下文的动机是找到形状之间的对应关系。但是,形状上下文本身仅用作形状描述符,其任务是捕获局部相似性。因此研究人员需要另一种方法来构建形状之间的对应关系。在本文中,我们还通过将时间序列视为两个相似形状的一部分来采用形状对应的思想。因此,我们将简要回顾一下形状对应的方法。有兴趣的读者可以参考[41]进行关于形状对应的研究方法综述,其中回顾了不同类型表示下的形状方法。找到最佳对应关系的一个常见范例是设计一个衡量每个潜在解决方案质量的目标函数。然后,问题转换为优化问题。在[10]中仔细讨论了两种典型的优化方法,动态规划和图算法,以及它们在计算机视觉中的应用。在形状背景的协同作用下,采用正则化的薄板样条模型[8,30]来估计形状对应[3]。为了找到各组图像之间建立的对应关系,[51]使用了零件几何模[9,12,5,11]。[15]提出了一种分层稀疏图匹配方法,其中两种可能匹配之间的成对协议以线补丁的新概念为特征,并引入稀疏约束来抑制模糊匹配的影响。为了建立如[20]所述的圆柱形拓扑形状的良好对应,使用圆柱参数化来提供初始对应关系;描述长度用于通信质量;和圆柱形b样条变形用于通过变形参数化来改善对应关系。在本文中,由于目标是时间序列,因此采用DTW作为优化方法来找到最佳对应关系(对齐)。
3.SC-DTW
3.1 在DTW中引入形状上下文
基于DTW和形状上下文,SC-DTW算法非常简单。 当找到两个时间序列之间的对齐时,我们使用形状上下文之间的成本来替换原始基本距离。 图5示出了新基距离下的一对对应点。 我们首先计算每个点的形状上下文,然后将每对点之间的新基本距离定义为:
必须明确的一点是SC-DTW仅使用形状上下文来生成时间序列之间的对齐,累积距离仍然是根据原始基本距离计算的。从逻辑上讲,DTW应该分解为两个步骤。第一步是找到两个时间序列之间的最佳对应,第二步是根据对应计算每对点之间的原始距离。实验中,DTW中的两个步骤是合并在一起的,因为他们使用的都是相同基础距离,但在SC-DTW中,考虑了不同的特征,在两步中使用了不同的基础距离。形状上下文仅为我们寻找一个合理的特征与特征之间的对应,形状上下文之间的成本基于卡方检验,因此它不是合适的距离度量。 因此,我们仍然在最后一步中使用原始基本距离,以便SC-DTW的行为更类似于距离度量。
SC-DTW算法流程如下:<!--
全文共9811字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[3040]

