
英语原文共 5 页,剩余内容已隐藏,支付完成后下载完整资料
2 k-means算法
2.1算法
k-means算法是一种简单的迭代方法,用于将给定的数据集划分为用户指定数量的簇: k。该算法已被不同学科的研究人员进行广泛研究,最著名的是Lloyd(1957,1982)、Forgey(1965)、Friedman and Rubin(1967),和McQueen(1967),关于k-均值的详细研究史以及演化情况的描述在[43]中给出。Gray和Neuhoff为k-means在爬山算法 (hill-climbing) 中的应用提供了一个很好的历史背景。该算法在一组d维向量上进行操作,,其中 表示第个数据点。该算法通过选取中的k个点作为初始的k个“簇代表”或质心,即就是初始种子点。选择这些初始种子点的手段包括从数据集中随机抽样、将初始点设置为对数据的一小部分进行聚类或者采用对数据的全局平均值进行k次扰动的解决方案。然后算法在两个步骤之间迭代直到收敛:
步骤1:数据分配。每个数据点被分配到其离其最近的质心,连接可以任意断开。以此来对数据进行分区。
步骤2:“means”的重新定位。每个集群代表被重新定位到分配给它的所有数据点的中心(平均值)。如果数据点带有概率度量(权重),则将质心重新定位到数据分区的期望值(加权平均值)。
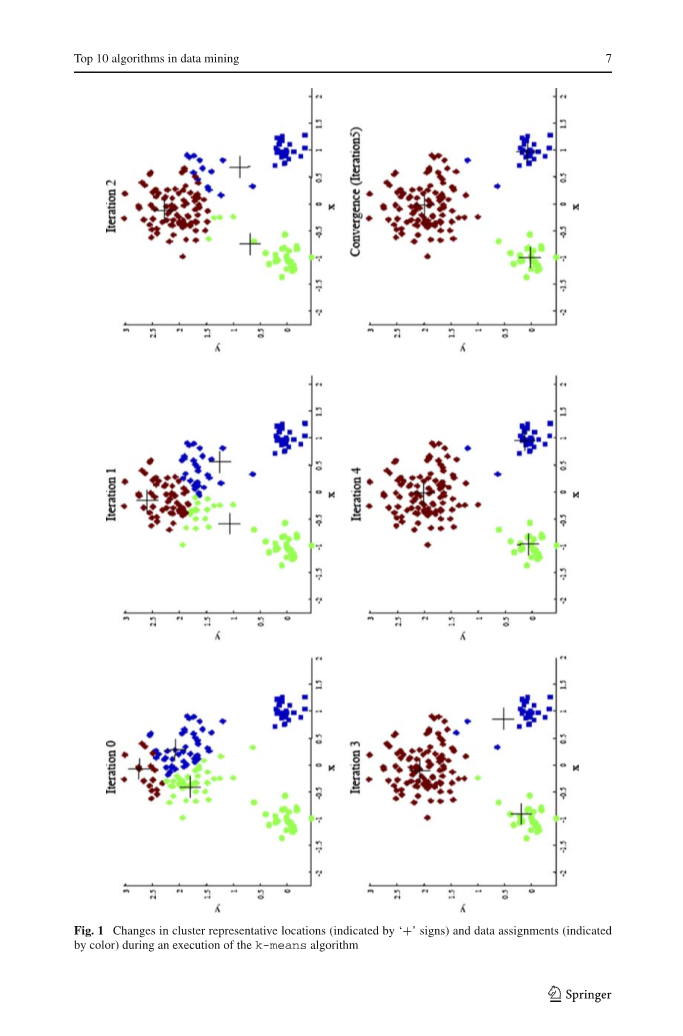
当means的赋值()不再改变时,算法收敛。算法的执行如图1所示。注意,每次迭代需要Ntimes;k次比较,这决定了一次迭代的时间复杂度。收敛所需的迭代次数是变化的,并且可能取决于N,但是作为第一次切割,该算法在数据集大小上可以被认为是线性的。
有一个需要我们解决的问题:如何在分配过程中来衡量什么是所谓“最接近的”。接近程度的默认度量是欧几里德距离,在这种情况下,我们可以很容易地证明对于非负成本函数,
当分配或位置步骤发生变化时,值将减少,因此该函数在有限的迭代次数中将保证收敛。k-means在非凸代价下的贪婪下降性质也意味着收敛仅限于局部最优,初始质心位置的选择对于算法来说非常重要。图2表示出了在与图1中相同的数据集中,因为对于三个初始质心的选择不同,而获得了较差的结果。在不同的初始质心下多次运行该算法,或对收敛解进行有限的局部搜索,可以在一定程度上克服局部极小问题。
图1: 在执行k均值算法期间,群集代表位置(以“ ”表示)和数据分配(以颜色表示)的变化
图2: 初始化对k-均值结果的影响
2.2局限性
除了对质心的初始化敏感外,k-means算法还面临其他一些问题。首先,观察到k均值是由k个具有相同的各向同性协方差矩阵()的k高斯混合而成的拟合数据的极限情况,这是因为将数据点的软分配 (Soft assignments) 硬性地分配给每个混合分量数据仅指向最可能的组件。因此,每当数据没有被合理地分离和描述时,它就会动摇,例如,如果数据中存在非凸形的簇。通过在群集之前重新缩放数据以 “whiten” 数据或使用更适合数据集的不同距离度量,可以缓解此问题。例如,信息理论聚类使用KL散度测量代表两个离散概率分布的两个数据点之间的距离。最近有研究表明,如果在分配步骤中通过选择称为Bregman散度的非常大的散度中的任何一个成员来测量距离并且不进行任何其他更改,则k-means的基本属性包括保证的会聚,线性分离边界和可扩展性,得以保留。只要使用适当的散度,此结果就可以使k-means对更大类别的数据集有效。
k-means可以与另一种算法配对以描述非凸簇。首先使用k-means将数据聚类为大量组。然后使用单链路分层聚类将这些组聚集成更大的聚类,从而可以检测复杂的形状。这种方法还使解决方案对初始化的敏感性降低,并且由于分层方法可提供多种分辨率的结果,因此也无需预先指定k。
最佳解决方案的成本随着k的增加而降低,直到当簇数等于不同数据点的数量时它达到零。这使得(a)直接比较具有不同数目的聚类的解决方案和(b)找到k的最优值变得更加困难。如果所需的k事先未知,则通常会使用不同的k值运行k-means,然后使用合适的标准选择结果之一。例如,SAS使用多维数据集聚标准,而X均值将复杂度项(随k增加)添加到原始成本函数(公式1)中,然后标识k,从而使此调整后的成本最小化。或者,可以结合适当的停止标准逐渐增加群集的数量。均分k-means通过首先将所有数据放入单个群集中,然后使用2均值递归将最小压缩量群集分为两个来实现。使用用于矢量量化的著名的LBG算法使簇数加倍,直到获得合适的代码大小。因此,这两种方法都减轻了事先知道k的需要。
该算法对异常值的存在也很敏感,因为“均值”不是一个稳健的统计量。去除异常值的预处理步骤可能会有帮助。对结果进行后处理,例如消除小的集群,或者将紧密的集群合并为大的集群,也是可取的。Ball和Hall 1967年的ISODATA算法有效地使用了k-means的预处理和后处理。
2.3归纳与联系
如前所述,k-means与将k各向同性高斯混合到数据中密切相关。此外,对所有布瑞格曼发散的距离度量的推广与用指数分布族的k个混合分量拟合数据有关。另一个广义的概括是把“均值”看作概率模型,而不是中的点。这里,在赋值步骤中,将每个数据点分配给最有可能生成它的模型。在“重定位”步骤中,模型参数被更新为最适合指定的数据集。这种基于模型的k-means允许我们去迎合更复杂的数据,例如由隐马尔可夫模型 (Hidden Markov Models)描述的序列。
我们也可以“内核化” k-means。尽管聚类之间的边界在隐式高维空间中仍然是线性的,但当投影回原始空间时它们可能变为非线性,从而使核k-means可以处理更复杂的聚类。 Dhillon等。已经显示出内核k-means和频谱聚类之间的紧密联系。除了质心必须属于正在聚类的数据集之外,K型算法与k-means算法相似。模糊c均值也与此类似,除了它为每个聚类而不是一个硬聚类计算模糊隶属度函数(fuzzy membership functions)。
尽管存在缺点,但k-means算法仍然是在实践中使用最广泛的分区聚类算法。该算法简单,易于理解且具有合理的可扩展性,并且可以轻松修改以处理流数据。为了处理非常大的数据集,还付出了更大的努力来进一步加快k-means的速度,特别是通过使用kd树(kd-trees)或利用三角不等式来避免在分配步骤中将每个数据点与所有质心进行比较。对基本算法的不断改进和推广,确保了其持续的适用性并逐渐提高了其有效性。
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[238783],资料为PDF文档或Word文档,PDF文档可免费转换为Word

