
英语原文共 19 页,剩余内容已隐藏,支付完成后下载完整资料
二项式置信区间和应急测试:数学基本原理和替代方法评估
Sean Wallis
University College London
摘要:许多统计方法依赖于基于a的概率数学模型 简单的近似,同时是众所周知的,但常常不甚了解。 这个 近似值是二项分布的正态近似值,它支持一系列统计量 测试和方法,包括计算准确的置信区间,表现出良好的配合度 应急测试,线条和模型拟合以及基于这些的计算方法。 这些方法有什么共同之处在于假设可能的分布错误 观察结果正常分布。 这个假设允许我们构造比想象更简单的方法 否则是可能的。 然而这个假设从根本上是有缺陷的。 本文分为两部分:基础和评估。 首先,我们检查错误的估计 使用三种方法:Wald(正常)间隔,Wilson评分间隔和确切Clopper-Pearson 二项式间隔。 而前两个可以直接从公式计算,二项式间隔必须是 通过计算搜索近似,并且在计算上是昂贵的。 但是这个间隔 提供了最精确的重要性测试,因此将成为我们后续评估的基准。 我们 考虑两种进一步的改进:在计算间隔中使用对数似然(还需要搜索)和 为从离散分布到连续分布的转换添加校正的效果。 在本文的第二部分,我们考虑对这一系列的三种截然不同的方法进行全面评估 测试范例。 这些范例是适合性测试的单个区间或2times;1个善良,以及两个范围的变化 常见的2times;2应急测试。 我们通过“从业者战略”评估每种方法的表现。 由于标准的建议是在预期近似值的条件下回退到“确切的”二项式测试 如果失败,我们只需计算一次测试获得相同结果的实例的数量 精确的测试并不能涵盖所有可能的值。 我们证明最佳方法是基于Wilson间隔或连续性纠正版本 耶茨测试,以及有关的chi;2测试弱点普遍持有的假设是误导性的。 数似然, 经常提议作为对chi;2的改进 ,令人失望的执行。 在这个精度水平,我们注意到我们 可以根据自变量是否将数据分割成两部分来区分两种2times;2测试 独立人群,我们为他们的使用提出切实的建议。
关键词:卡方,对数似然,应急测试,置信区间,z检验,威尔逊得分间隔, Newcombe-Wilson测试,独立人群
- 介绍
估计观察中的误差是推理统计中的第一步,也是至关重要的一步。它使我们能够对我们多次重复实验会发生什么做出预测,并且因为每个观察都代表了一个人口样本,所以预测了人口的真实价值。考虑一个观察结果,大小为n的样本的比例 p是特定类型的。例如 :
bull;掷硬币的一组n 的比率 P抛出的头,
bull;一年内发生故障的n个灯泡生产中灯泡 p 的比例 ,
bull;患者的 P谁药物试验后,有六个月内第二心脏发作的比例( n是试验中的患者人数),
bull;疑问句条款n的口语语料库是有限的比重。
因为进行了一次实验,我们对P进行的一次观察。我们希望通过现在推断未来。 我们想知道我们对 p 的观察的可靠性在没有进一步采样的情况下。 很明显,如果药物可能会出现,我们不想重复对心脏病患者进行药物试验从而影响他们的身体状况。
- 计算置信区间
我们需要估计误差幅度或使用我们的正确的术语, 置信区间观察。 置信区间告诉我们, 在给定的确定水平上,如果我们的科学模型是正确的话,人口的真实价值可能会在确定的范围内。置信区间越大,观察结果就越不确定。有几种不同的方法去计算置信区间,我们将从讨论最常用的方法开始。
2.1Wald间隔
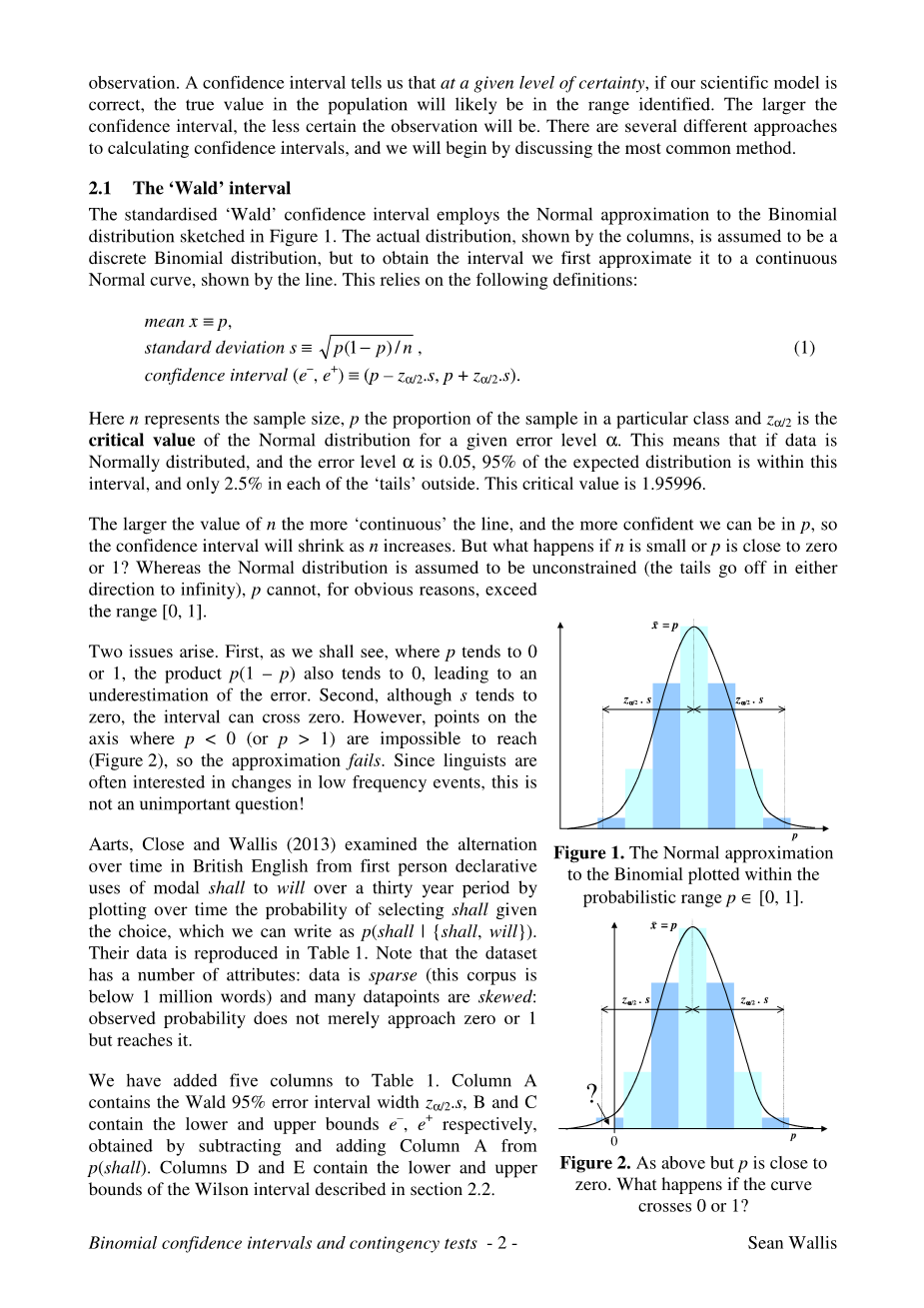
标准化的Wald置信区间采用二项式的正态近似。分布如图1所示。实际分布(由列显示)假定为离散二项分布,但要获得间隔,我们需要首先将其近似为连续的正常曲线,这依赖于以下定义:
均值 ,
标准偏差 , (1)
置信区间
在这里,n表示样品大小,对所述样品中的特定类以及是给定误差水平的正态分布的临界值。这意味着如果数据是正态分布,误差水平为0.05,预期分布的95%在此范围内间隔,在每个“尾巴”外面只有2.5%。 这个临界值是1.95996。n 的值越大,线越“连续”,我们就越有信心p在其中 ,所以 随着 n增加,置信区间将缩小 。 但是,如果n很小或p接近零或1,会发生什么情况? 而正态分布被假定为无约束的(尾部在两个方向都会发生) 方向到无穷大),但由于显而易见的原因,p不能超过范围[0,1]。
这里出现两个问题。首先,我们将看到, p趋于0 或1,也倾向于0,导致低估错误。 其次,虽然s趋于零,间隔可以经过零。 但是,当p lt;0(或p gt; 1)所有点不可能经过0 (图2),所以近似失败。由于语言学家 往往对低频事件感兴趣,这是一个重要问题。
图1 正态近似到二项式内绘制的概率范围pisin;[0,1]
图2
Aarts,Close和Wallis(2013)对交替进行了研究。随着时间的推移,根据英国英语第一人称声明模式的使用,在三十年里,随时间绘制给出这些选择的可能性,我们可以写成。 他们的数据转载于表1中。请注意数据集有一些属性:数据的特点是是稀疏(低于100万字)和许多数据点偏斜:观察到的概率不仅接近零或1 但能到达它。我们在表1中增加了五列,列A包含Wald95%的误差间隔宽度。 s ,B和C包含下限和上限 e - ,e ,通过从中减去并添加列A从而获得 p。列D和E包含在2.2节中描述的Wilson间隔的界限下部和上部。
表1第一人称陈述模态的交替与最近一段时间的数据相比较
当p(shall)=0或者1时,值是完全偏斜的,从而获得零宽度间隔,粗体高亮显示在A列中。然而,零宽度的间隔表示完全确定性。 我们不能说,基于一个观察结果,即1958年所有类似采样的说话者都可以代替第一人称陈述的意愿!其次,C列提供了两个超调的例子(1960,1970),其间隔的上限超出范围 [0,1]。同样,如图2所示,概率范围之外的任何部分都是简单的。如果无法获得,表明间隔是计算错误的。为了说明这一点,我们在图3绘制了表1 数据。
共同统计建议(即3-sigma规则)不法分子极值,并且在使用Wald间隔之前需要满足 pplusmn;3 秒。99.7%正态分布应该在3个标准之内 平均值的偏差。然而,这条规则对我们的影响只是放弃错误估计。
图3 .随着时间的推移p(shall)的图 ,来自表1的数据,具有95%的Wald间隔
对于低或高的 p值或极小的n值的情况,该方法的结果并不能让人满意!表1中的不到一半的满足这个规则(图3中的空白点)。类似的启发式测试(Cochran规则)避免了在预期单元格内使用价值低于5分的进行测试。这一结果已被证明非常令人不满,以至于一系列统计人员在一系列的尝试应对低频率和偏斜的数据集后,提出了这样的建议寻找卡方检验替代品,如对数似然检验。在本文中,我们得出了Wald时间间隔的问题 - 它不正确地描述关于P的时间间隔和它未能纠正连续性 - 然后通过绘图极限和详尽的计算两种方式组合来评估竞争性测试方法。
2.2威尔逊得分区间
传统Wald定义的关键问题是置信区间不正确这一特点。请注意我们如何假设关于p的区间,假设其是近似于正态分布的二项式。 这是思考问题的错误方式,但它也是一个需要解决的常见错误。正确的表达有点违反直觉,但可以总结如下。
设想一个真正的总体概率,我们称之为 P。 这是实际的价值 人口。关于P的观察将根据二项式分配。 我们不知道 确切地说 P是什么 ,但我们可以尝试间接地观察它,通过对人口进行抽样。
给定的观察 P,有潜在的,这将代替对在最外P的两个值。关于P的置信区间的限制,参见图4.因此,我们可以做的就是搜索满足以下公式的 P 值,用于表征法的近似值。
关于的二项式,我们给出如下定义:
总体均值
总体标准差 (2)
群体置信区间
公式与(1)相同,但符号已更改。符号和,指的是分别是常用的人口均值和标准差。这个人口置信区间确定了两个极限情况。其中,
现在考虑样本观察p周围的置信区间。 我们不知道以上的p,所以我们不能计算这个想象的人口置信区间.这是一个理论概念!
然而,以下区间平等原则必须成立,其中e - 和 e 是更低和任何错误级别的采样间隔的上限:
当,
当, (3)
如果 p 的下界 (标为e -)是可能的总体均值,则上粘结的将是 p ,反之亦然。 由于我们有一个公式的上限和下限间隔。我们可以尝试找到满足和的值。
通过计算机,我们在正确的价值观上可以执行搜索过程以实现融合。上面的人口置信区间的公式是一个关于公式 z 的正态 z区间 人口概率 P。 这个间隔可以用来进行人口的z检验可能性。这个测试相当于2times;1的拟合优度测试,人口概率就是预期概率。
幸运的是,不通过执行计算搜索过程,我们发现有一个 直接计算关于 p 的采样间隔的简单方法。这个间隔被称为威尔逊评分间隔 (威尔逊,1927年),可写成:
威尔逊得分区间 (4)
评分间隔可以在正负号(plusmn;)符号的任一侧分解为两部分:
1) 重新安置的中心估计值
- 校正的标准偏差
我们将使用小写w代表威尔逊区间。
关于人口分布的2times;1拟合优度chi; 2 测试样本概率落入高斯时间间隔内,即
在样本置信区间内的概率这与测试人群的结果相同,我们发现那里,,如图4所示。正如图所示,正态分布是对称的,威尔逊区间是不对称的(除非 p = 0.5)。
图4 区间平等原则 与正常和威尔逊间隔
在样本上使用Wilson间隔 概率本身并没有改善这个,通过接近获得完全相同的结果,这个问题来自 p而不是P。 改进是在估计围绕 p 的置信区间 !
如果我们回到表1,我们现在可以绘制在第一人称在时间间隔上,使用 Wilson上限和下限得分区间界限在列D和E,图5描述了相同的数据。 以前的零宽度区间有很大的宽度,这正如人们所期望的那样,它们具有很高的观察不确定性,而不是在一些实例中,扩展了近80%的概率范围。在图3中超过1960年和1970年的数据点落入概率范围内。几乎延伸到整个1969年 和1972年。
图5 随着时间的推移p(shall)的图 ,来自表1的数据,具有95%的Wilson得分置信区间
这些间隔如何进行总体比较? 正如我们所看到的,威尔逊区间是不对称的。 在 公式4,中心点p被推向概率范围的中心。此外,间隔的总宽度是,即与s成比例。 我们通过绘图来比较s和s跨越 p对于图6中的样本大小n的不同值。请注意,Wilson偏差s从不对于低或高p值达到零,而高斯偏差总是收敛于0极端(因此零宽度间隔行为)。曲线之间的差异随着增加 n (更低),但这个极端值的问题需要继续wald间隔。
图6 Wald和Wilson 标准偏差 s ,s ,pisin;[0,1]
2.3确切二项式间隔
到目前为止,我们已经使用了Normal的 近似值二项分布,并对照沃尔德和威尔逊 方法。根据理想分布评估公式,但是我们需要一个基线。我们首先需要计算原则 P值。 为此,我们使用二项式公式。从图1可以看出,二项分布是离散分布,即它可以表示为一个有限的系列针对 x = {0,1,2,3,..., n }的不同值的概率值。
我们将考虑 p 的下界,即(如图4)。 每个区域都有两个区间边界概率,但论证是对称的:我们可以申请用相同的计算代替 q = 1 - p等等,如下展示一些例子。
考虑一个投掷硬币的实验,我们抛弃一个加权投球硬币 n次,并获得r头(有时称为伯努利试验)。这个硬币有一个重量 P ,即真实值 获得头的人口是P ,并且a的概率是(1 - P ),硬币可能有偏差,所以P不必为0.5!
在一个重量为P的硬币的n个掷币中, r的头部的二项式分布定义如下,其用于 r 的一系列离散概率的条件,其中每列的高度由下式定义:
二项式概率:
(5)
到二项列的总面积:
(6)
但是,这个公式假定我们知道P。我们想在a处找到p = x / n的确切上界 给定错误级别alpha;。 Clopper-Pearson方法采用计算搜索程序进行求和 从 x到n 的上部尾部找到P在哪里 其认为:
这会得到任何整数 x 的精确结果。计算机修改 P 的值直到公式为曲线下的剩余尾部区域收敛所需的值。
请注意,这种方法与置信区间观察 p的思想是一致的:识别a 点 P,从对足够远的p是被认为与 P有显着不同级别。 如第2.2节所述, 我们不知道人口价值 P真实情况,但我们预计数据会是项式分布在它周围。图7显示了计算较低的结果 使用这个Binomial公式来定义p = P。我们也绘制威尔逊公式,有和没有调整称为“连续性修正”,我们将在下一节讨论。正如我们已经指出的那样威尔逊公式为p相当于一个2times;1的适合且基于 P。 连续性校正公式 与Yates的2times;1times;相似。所有三种方法获得较低的置信区间 p在x = 0时倾向于零,但不会在 x = n时收敛为零。即使是一个小样本,n = 5,连续性纠正的威尔逊间隔非常接近。确切人口二项式使用搜索过程获得,但它更容易计算。
图
剩余内容已隐藏,支付完成后下载完整资料
资料编号:[23037],资料为PDF文档或Word文档,PDF文档可免费转换为Word

