
英语原文共 6 页,剩余内容已隐藏,支付完成后下载完整资料
水质量模型中可靠适用的决策树适用性指标
G. Everaert , E. Bennetsen , P.L.M. Goethals
摘 要
数据驱动的环境模型主要根据其模型拟合进行评估,而对其最终用户的适用性只给予有限的关注。在本文中,我们提出了适用性指数(API),它根据最终用户的可解释性和适用性对决策树进行评分。该API集成了两个标准。即模型的简单性以及预测响应变量的类别的能力。我们开发了10,000种具有不同参数的决策树,并评估了使用API进行模型选择时使用两种不同的数据集。 API将只根据统计标准保留的决策树的数量分别从2,806个减少到173个,1,117个减少到784个。保留的模型更容易解释,统计可靠但不太复杂。传统统计学标准如Cohen的 kappa和正确分类实例的数量与API只有中等程度的相关性(分别为r = 0.26和r = 0.49)。这表明API对现有模型选择可用统计标准是一个有用的补充。对API进行了两个数据集的测试,包括比利时和荷兰低地河流的水质数据,因此其有效性还需要针对其他类型的数据和建模领域来进行测试。
关键词:决策树、决策制定、淡水生态、水质管理、低地国家
介绍
环境模型有助于概念化生态系统(Guisan 和 Zimmerman, 2000)。它们常常作为理论支撑被应用到河流管理决策中,例如,在生态研究中(Everaert 等., 2013a; Holguin-Gonzalez 等., 2013; Mouton 等., 2007)或降雨径流的研究中(Valipour, 2015, Valipour 等, 2013)。决策树已经被应用到环境背景中(e.g. Dzeroski 和 Drumm, 2003; Gal 等., 2011; Tirelli 和 Pessani, 2011)。决策树是一种黑盒模型,通过在确定阈值中划分预测变量来解释响应变量的变化(De#39;ath 和 Fabricius, 2000)。它们由一套透明的知识规则组成,不涉及到专业领域的知识,由数据直接推导出来((De#39;ath 和 Fabricius, 2000; Lees 和 Ritman, 1991)。它们特别有用,因为可靠的分类与一组透明的规则相结合,能被决策者轻松理解(Goethals 等., 2007)。
决策树主要用统计可靠性来评估(Bennett 等., 2013)。然而,统计指标的最大化并不总是指向最优化的模型(Everaert 等., 2013b)。决策树可以很大且很难被解释(Breslow 和 Aha, 1997),但是很少有研究承担起提高最终用户对其理解度的责任(Huysmans 等., 2011; Osei-Bryson, 2008)。通常,对于验证数据,环境决策树显示出足够的统计可靠性,但难以被最终用户所应用(Larocque 等.,2011)。例如,OseiBryson(2008)指出,只评估统计可靠性时,将在决策树上选择准确率为0.959和29叶子节点的决策树而不是准确率为0.958和5叶子节点的决策树。最近Stiglic等人(2012)将可视化调整的决策树与通过默认参数产生的模型进行了比较。他们发现,通过可视化调整的决策树比默认模型的决策树更简洁,但两种方法的预测性能没有差异。因此,除了统计可靠性之外,决策树的可理解性和适用性在最终产品的评估中值得关注(Voinov 和 Bousquet, 2010)。例如,Everaert等人(2013a)将权益人的观点纳入模型评估中,因为根据他们的专业知识,利益相关者可以对所发现的理论关系给出反馈。总体而言,其他质量方面的统计可靠性在模型评估中同样重要(Jakeman 等., 2006; Larocque 等., 2011)。因此,新的质量标准,如环境模型对于最终用户的可理解性和适用性,应当被客观地结合到当前的评估标准中。虽然已经有一些理论方法(e.g. OseiBryson, 2008)和决策树可视化调整的例子(e.g. Stiglic 等., 2012),根据作者所知,决策树在决策支持中适用性的客观评估方法尚未被开发。为弥补这一缺陷,我们在本研究中提出了一个指标,来客观地选择对最终用户(例如决策者)有用的决策树。适用性指数(API)评估决策树的简洁性和可解释性。 API通过集成视觉简单性和预测响应变量的所有类别的能力,客观而透明地量化模型对最终用户的有用程度。我们分析了两个包括法兰德斯(比利时)和荷兰地表水水质数据的大范围数据集,并根据常规使用的统计标准测试了模型选择中适用性指数的附加值。最后,API的鲁棒性是在独立验证的基础上评估的。
材料与方法
可用性指标的两个度量
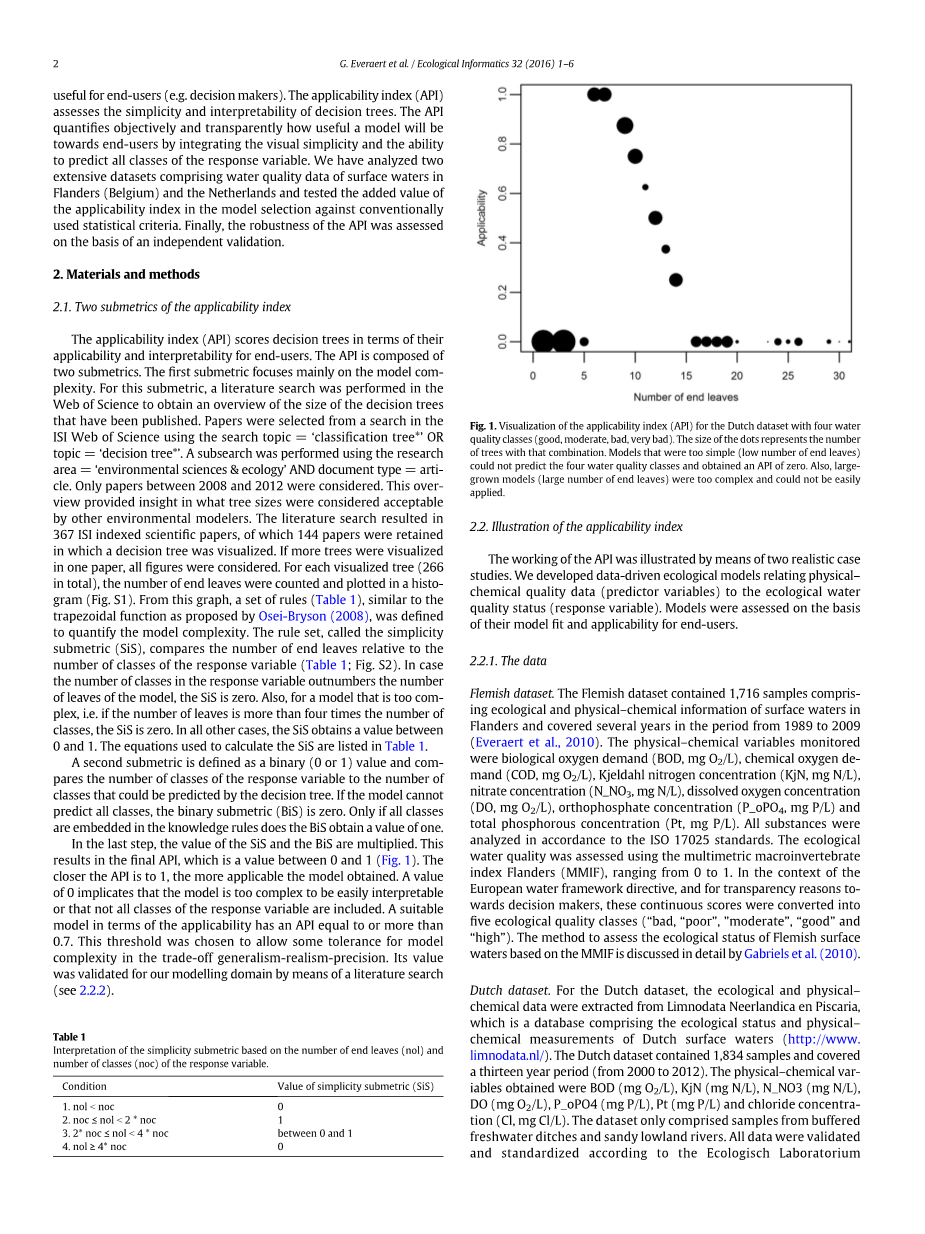
适用性指数(API)根据最终用户的适用性和可解释性对决策树进行评分。该API由两个子计量组成。第一个子计量主要关注模型的复杂性。对于这种分类,在Web of Science中进行了文献检索,来获得已发布的决策树大小的概述。论文选自ISI Web of Science中使用#39;分类树*#39;或#39;决策树*#39;关键字搜索的结果。使用范围关键字=#39;环境科学与生态学#39;和文献类型=lsquo;文章rsquo;进行了一项搜索。只考虑2008~2012年间的论文。概括地提供了有关其他环境建模者认为的可以接受的决策树大小的见解。文献检索得到了367份ISI索引科学论文,其中144篇论文关注于决策树可视化。如果在一篇论文中看到更多的决策树,所有数据都将被考虑。对于每个可视化决策树(总计266个),计算末端叶片的数量并绘制成图表(图S1)。从该图中,一组类似于Osei-Bryson(2008)提出的梯形函数的规则(表1)被定义,用于量化模型的复杂性。这组规则被称为简单度量(SiS),比较末端叶子的数量与响应变量的类数(表1;图S2)。如果响应变量中的类数超过了模型的叶数,则SiS为零。另外,对于过于复杂的模型,即如果树叶的数量超过类数的四倍,则SiS为零。在所有其他情况下,SiS的值介于0和1之间。用于计算SiS的公式见表1中。
第二个子度量定义为二进制值(0或1),并将响应变量的类数与可被决策树预测的类数进行比较。如果这个模型无法预测所有类别,则二进制值(BiS)为零。只有所有类都考虑了知识规则,BiS才为二进制1。
在最后一步中,SiS和BiS的值相乘。这将得出最终的介于0和1之间的API值(图1)。 API越接近1,所得模型适用性越强。值为0意味着模型太复杂以至于很难解释,或者并非所有类别的响应变量都被考虑在其中。就适用性而言,适用性强的模型具有大于等于0.7的API值。选择这个阈值是为了权衡通用性-真实性-精确度而对模型复杂度的一些容忍。通过文献检索,我们验证了它对建模领域的价值。(见2.2.2)
表一
根据响应变量的结束叶数(nol)和类数(noc)来解释简单度量
图1荷兰数据库对四个水质类别(好,中,差,非常差)的适用性指数(API)的可视化图表。该树木数量组合的简化表示。模型简单(数量较少的端叶)以至于不能预测四个水质类别,并且获得API为零。此外,大型模型(大量尾叶)太复杂,难以被应用。
适用性指标说明
通过两个实际案例学习来说明API的工作。 我们开发了数据驱动的生态模型,将物理-化学品质数据(预测变量)与生态水质状况(响应变量)相关联。 根据模型对最终用户的适用性来对模型进行评估。
2.2.1 数据
佛兰德斯数据集。佛兰德斯数据库包含1,716个样本,包括法兰德斯地表水的生态和物理化学信息,涵盖了1989年至2009年期间的数据(Everaert 等., 2010)。监测的生物需氧量(BOD,mg O2 / L),化学需氧量(COD,mg O2 / L),凯氏氮浓度(KjN,mg N / L),硝酸盐浓度(N_NO3,mg N / L),溶解氧浓度(DO,mg O2 / L),正磷酸盐浓度(P_oPO4,mg P / L)和总磷浓度(Pt,mg P / L)。所有物质均按照ISO 17025标准分析。使用MMIF评估生态水质,范围从0到1。在欧洲水管理框架的前提下,为了向决策者提供解释,这些连续数据被转换为五个生态质量等级(“很差”,“差”,“中等”,“高”和“很高”)。 Gabriels等人详细讨论了基于MMIF评估佛兰德斯地表水生态状况的方法。 (2010年)。
荷兰数据集。对于荷兰数据集,生态和物理化学数据是从Limnodata Neerl和ica en Piscaria提取的,该数据库是荷兰地表水生态状况和物理化学测量的数据库(http:// www。limnodata.nl/)。荷兰数据集包含1,834个样本,涵盖了13年的数据(从2000年到2012年)。所得物理化学变量为BOD(mg O2 / L),KjN(mg N / L),N_NO3(mg N / L),DO(mg O2 / L),P_oPO4(mg P / L),Pt P / L)和氯化物浓度(Cl,mg Cl / L)。该数据集仅包含来自缓冲淡水沟渠和沙低低地河流的样本。所有数据都根据Ecologisch Laboratorium InforMatieSysteem格式(de la Haye 等。,2011)进行了验证和标准化。生态水质量基于EQR进行量化,范围从0到1。这些值与Flemish数据集类似,转换为五个生态质量等级(“很差”,“差“,”中等“,”高“和”很高“)。 Buskens等人详细讨论了基于EQR评估荷兰地表水生态状况的方法。 (2007年)。
2.2.2 决策树
数据探索。计算Spearman相关系数以探索物理-化学变量之间的关系(表S1)。当变量显示共线性时,只有一个被保留在数据集中(Zuur 等。,2010)。此外,不是所有被量化的变量都被丢弃, 这里定义1-99百分位以外的值才被排除。结果,佛兰德斯和荷兰数据集分别保留873和551个样本(表S2)。 MMIF和EQR的分布中,高和很高的等级分类最不具有代表性(图S3A和S3B)。因此,EQR的高和很高的等级分类合并为一类(高-很高;佛兰德斯和荷兰数据集中分别为n = 47和n = 39)(表S2)。在我们的分析中,生态水质是响应变量,而物理化学变量则用作预测因素。
模型开发和评估。模型训练和验证基于k折叠交叉验证程序(Witten和Frank,2005),据此原始数据库被随机分为k个子数据集。其中,一个subdataset用于模型验证和其余k-1个数据集用于模型训练。该过程重复了k次,每个子数据集用于验证数据集一次。生成决策树的叶子节点代表了生态状况(Everaert 等。,2013a)。通过执行10,000个随机模型参数来评估模型的稳定性。三个模型参数随机变化(表S3)。复杂度参数(数值介于0.001和0.1之间),最小对象数量(介于1和最不具有生态质量代表性的个案数量之间的整数值)和折叠交叉验证的数量(1到20之间的整数值)。所有决策树均使用R(R开发核心团队,2013)中的rpart包来建立。
对10,000种不同参数化所获得的决策树进行了统计性能评估和对最终用户的适用性评估。使用正确分类实例(CCI)和Cohen#39;s kappa统计量(kappa;)的百分比,基于混淆矩阵评估模型拟合对模型适用度进行评估。 CCI为真实的正面和负面预测的百分比计算。 kappa;测量了真正的正面和负面的预测的百分比值,但是调整了这些数值以达到预期的一致性(Cohen,1960; Hoang等人,2010)。API如前文计算(参见2.1),并用它来评估决策树的适用性。
荟萃分析。荟萃分析的目的是评估在选择最终模型结构时使用API作为常规统计标准的附加价值。建模产生了两组10,000棵的树,这意味着每个数据集有一组树。对于每组树,计算模型参数化与CCI,kappa;和API之间的Spearman相关系数。其次,我们比较了基于CCI和kappa;选择的模型数量以及基于CCI,kappa;和API选择的模型数量。根据以下标准选择可接受的树:kappa;超过0.3(Johnson和Kuhn,2013),CCI超过最普遍类别的百分比,分别为佛兰德斯,荷兰数据集的46%和53%(Johnson和Kuhn ,2013),并且API高于0.7。
独立验证。为了测试API的鲁棒性及其阈值,进行了独立验证。除了出版年,搜索标准与用于产生图S1和表1中列出规则的搜索标准相同。论文从ISI Web of Science中使用关键字=#39;分类树*#39;或#39;决策树*#39;的搜索中选择。使用范围关键字=#39;环境科学与生态学#39;和文献类型=文章进行了搜索。只考虑2013年发表的论文。总共发现了74份科学出版物,但只保留了那些与水质模型有关并描述了决策树的那些出版物(27篇论文),这导致数据库中有17种模型。接下来,我们将API的计算规则应用到论文中的决策树上,并验证API是否符合0.7阈值
结果和讨论
适用API作为CCI和kappa;的补充
适用性指数(API)减少了被接受的决策树的数量(图2和S4)。如果评估仅基于CCI和kappa;,则保留佛兰德斯数据集的2,806个决策树(图2)。然而,当API是CCI和kappa;的补充时,保留的模型数减少到173个(图2)。因此,2,806个模型中的2,633个模型被发现太过复杂或者无法预测所有生态水质类别。荷兰数据集得出了类似结论,即当使用CCI和kappa;时选择了1,114个决策树,但当API用作额外评估标准时只有784个被保留(图S4)。因此,在
全文共8530字,剩余内容已隐藏,支付完成后下载完整资料
资料编号:[14685],资料为PDF文档或Word文档,PDF文档可免费转换为Word
您可能感兴趣的文章
- 拟人手臂的轨迹规划与轨迹跟踪控制外文翻译资料
- 新型磁性辅助内窥镜系统在上消化道检查中应用的可行性 和安全性外文翻译资料
- 基于FPGA可编程逻辑器件的复合视频图像处理外文翻译资料
- 从被测的高频域原始信号中提取巴克豪森噪声外文翻译资料
- 重型机床z轴热误差混合建模方法外文翻译资料
- 一个红外浊度传感器:设计与应用外文翻译资料
- 用于控制食物烹饪过程的电子系统.外文翻译资料
- 关于液体介质中电磁流量计的设计和理论上存在的问题。第二部分:关于带电粒子产生的 噪声理论外文翻译资料
- 基于LabVIEW和Matlab的小波变换对非平稳信号的分析仿真外文翻译资料
- 应用于腹腔镜手术的新型膜式加热加湿器 的开发外文翻译资料

